JVM における G1GC とヒープの雑な話
はじめに
どうも、けんつです。GW は特に何もせず映画とチェスに勤しんでいたら気がついた時には連休は既に過去のものとなっていました。
やるやる詐欺をしてきた JVM の G1GC について基本的なことなどをまとめていこうと思い立ったので書きます。ヒープではない領域の話については以前書いたので割愛。
ヒープと GC の基本

雑な GC の基本
この辺を雑に書くと、オブジェクトが生成された場合はまず Eden 領域に配置されて、そこから Minor GC によって Survivor 領域に移されたり、Survivor 領域が足りなくなったら Tenured 領域に配置され、そこでも領域が足りなくなると Major GC で解放される。
もう少し細かく書くと、Eden 領域に配置されたオブジェクトは Minor GC が走った時に利用されていないオブジェクトを破棄して、利用されているオブジェクトを Survivor 領域に移動させる。Survivor 領域にも移動させられない場合 or 一定回数 Minor GC を生き残ったオブジェクトは Tenured 領域に移動させる。
Tenured 領域にオブジェクトを移動させることができない場合は Major GC が走って不要なオブジェクトを解放する。一般的にはこの時どちらの GC でも停止時間が発生する。特に Full GC の方が時間がかかりがち。
G1GC
概要
G1GC はそれなりに大きいメモリを持つマルチプロセッサマシンで高パフォーマンスを発揮する、正確には高いスループットを安定した一時停止時間目標内で実現することを目標としている。
さらに細かい要件では、6 GB 以上のヒープサイズを持つ JVM に対して 0.5 秒未満の安定した予測可能な一時停止時間を実現することを目的としている。*3
G1GC も世代別 GC となっているがヒープをリージョンという単位で分割し、管理している。その上でそれぞれのリージョンは Young 領域または Old 領域に属することとなる。この時、それぞれの領域に属するリージョンは必ずしも連続するとは限らない。また Tenured 領域に対する処理はバックグラウンドスレッドが行うため大抵の場合、アプリケーションスレッドは停止しない。その代わり複雑な処理を内部で行っているため CPU 使用率が高くなりやすい。
仕組み
G1GC は特に Old 領域に対する GC が他の GC アルゴリズムと異なる。Old 領域に対する GC では対象リージョン内にどれだけ不要となったオブジェクトが存在するかを基準にして領域を確保する。つまり不要オブジェクトが多いリージョンの操作に注力する。そのため短時間で GC を実行することが可能となる。この仕組みは Young 領域には適用されない。
その上で G1GC では次の 4 つの処理が中心となる。これらは別々に動作するわけではなく後述のコンカレントサイクル内で実行される場合がある。
Young 領域に対する GC
Young 領域に対する GC は Eden 空間*4を使い果たすと実行される。この時、Eden 空間は解放され最低でも一つの Survivor 空間が確保された上で必要に応じて Old 領域に移動される。
コンカレントサイクル
コンカレントサイクルは大まかに以下のフェーズから構成される。
- 初期マーク付け
Young 領域に対する GC に乗じて行われるためアプリケーションスレッドは停止する
- ルートリージョンスキャン
初期マーク付けでマークされた Survivor 領域を走査して、 Old 領域のオブジェクトに対する参照をマークする。次の停止を伴う Young 領域に対する GC が実行される前に完了している必要がある。このフェーズはアプリケーションスレッドと並列実行されるため停止を伴わない。ただし G1GC が利用するスレッドに対する CPU リソースが十分でない時は停止時間が増大する可能性がある。またこのフェーズは中断できないことに注意が必要。
- 並列マーク付け
このフェーズではヒープ全体が対象となり、オブジェクトグラフから到達可能なオブジェクトを探索する。これも並列実行されアプリケーションスレッドを停止させない。Young 領域に対する GC によって中断されることがある。
- 再マーク付け
未探索のオブジェクトグラフから到達可能なオブジェクトを再度探索する。アプリケーションスレッドの停止を伴う。
- クリーンアップ
領域を解放して、完全に利用していないリージョンと混合 GC で解放するオブジェクトを識別する。アプリケーションスレッドの停止を伴う。
ここで行っているのはあくまでも Old 領域に対するマーク付けで Young 領域に対する GC によって多少領域が解放されることはあるが、この一連のフェーズに色々期待してはいけないらしい。
混合 GC
バックグランドで実行されるコンカレントサイクルによって、リージョンに対するマーク付けが行われたらいよいよ混合 GC によって領域が解放される。混合 GC とは Young 領域に対する GC とマークがついたリージョンの解放が両方行われるため、そう呼ばれている。
Young 領域に対する GC では、Eden 空間が完全に空になり Survivor 空間に対して調整が入る。Old 空間に存在するマーク付けされたリージョンに対しては一度に全てを解放することはせずに、繰り返し実行される。その中でマーク付きリージョン内で到達可能なオブジェクトがマーク付きでない Old 領域のリージョンに退避される。マーク付きのリージョンがおおよそ解放された段階で Young 領域に対する GC が再開され、コンカレントサイクルによってマークされるを繰り返す。
Major GC が実行される可能性のある場合
- concurrent mode failure
マーク付けフェーズを開始し、完了するまでに Old 領域がいっぱいになった場合。この時該当するフェーズを中断して Major GC が走る。
- promotion failure
混合 GC が開始されたが、Old 領域に移動させる必要のあるものが解放されるものより多く、かつ Old 領域がいっぱいになってしまった場合。
- evacuation failure
Minor GC 時に Survivor 空間に十分な空きがなく対象となる全てオブジェクトを Old 領域に移動させる必要のある場合。リージョンが確保されているが、各リージョンでデータが断片化してしまった場合に起きやすい。必ず Major GC を伴うわけではないが、Major GC が走る可能性がある。またログ上では Minor GC として記録されているらしい。
おわりに
次は G1GC のチューニングにどういったものがあるのか調べようかね。疲れた。
参考文献
- ガベージファースト・ガベージ・コレクタ https://docs.oracle.com/javase/jp/8/docs/technotes/guides/vm/gctuning/g1_gc.html
- ガベージファースト・ガベージ・コレクタのチューニング https://docs.oracle.com/javase/jp/8/docs/technotes/guides/vm/gctuning/g1_gc_tuning.html
- 世代のサイズ設定 https://docs.oracle.com/javase/jp/8/docs/technotes/guides/vm/gctuning/sizing.html
- Java パフォーマンス
Java で利用できるオプションをバージョン別で比較してくれるサービスを作った話
2021/07/12 VPS が MariaDB ビルド用サーバに化けたのでサイトを運用していないです
はじめに
言語のバージョンを変更すると何らかの原因不明なトラブルに遭遇したりする場合がありますが、そういう時明確に機能変更などがあり原因がある程度サクッとわかる場合もあれば、一体どこか原因かわからないといった場合もあると思います。
それらの中で個人的にしんどいのが Java であればオプションのデフォルト値が変更になっていて、production build でそれらを指定していないがために暗黙的に性能劣化を引き起こしてしまうパターンに遭遇することです。
そういったときにどのバージョンからどのバージョンにあげると何が変わるのかということがサクッと見れると嬉しいですが、意外とそういうサービスがなく不便に思ったので作って見ました、という話です。
作ったもの
https://jvm.lrf141.dev/jvm.lrf141.dev
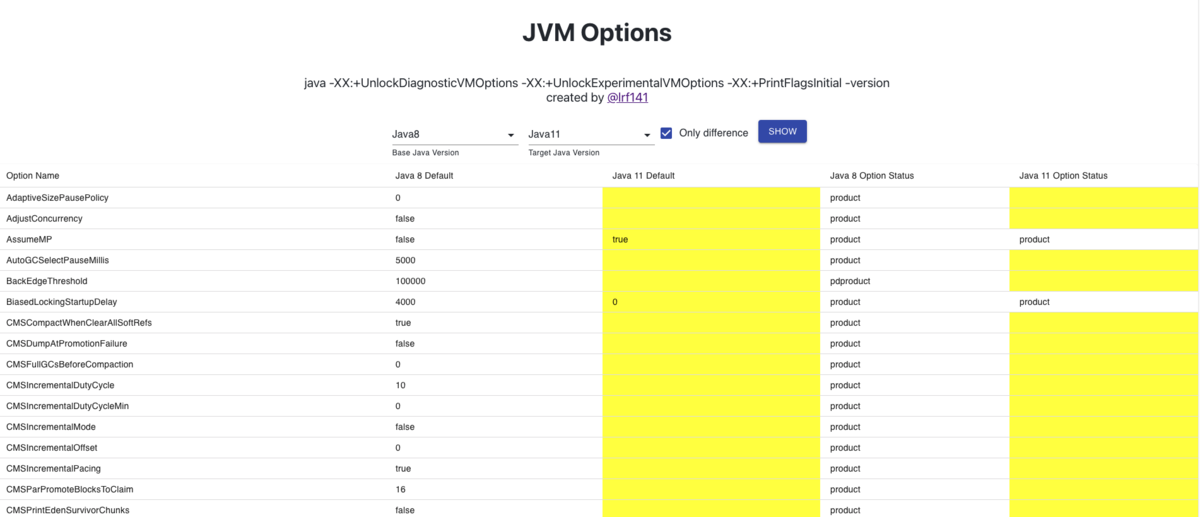
こんな感じのサービスを Springboot + Java 11, React で作成しました。
対象となるオプションたち
サイトタイトルの下にもありますが
java -XX:+UnlockDiagnosticVMOptions -XX:+UnlockExperimentalVMOptions -XX:+PrintFlagsInitial -version
各バージョン( 現段階では Java 8 ~ 11 の 4 バージョン ) でこれを実行し、json にした上で resoruces ディレクトリに配置し利用しています。
UnlockDiagnosticVMOptions
これは JVM の診断用オプションを有効にするためのオプションです。
診断用と言ってもなんだそれはとなりそうですが、例えば -XX:+LogCompilation や -XX:+PrintInlining といったオプションたちが当てはまります。
これによって色々捗る場合もあるので一応ここでは取得するオプションリストに突っ込んでいます。
UnlockExperimentalVMOptions
これは試験的に追加されているオプション群を利用可能にするというものです。
一応将来的にはサポート予定となっているオプションもあるようですが、基本的にその段階ではガチでサポートされていないオプションたちになります。
Experimental なオプションがその後サポートされたオプションになったケースもあるようで一応追加しています。
改善したい
一応それなりに使えるようにはなりましたが、フロントエンドの細かい部分とかめんどくさがって結構粗い実装になっていたりするので修正したいのと
諸事情でめちゃくちゃ急いで作ったため、バックエンド側のテストも不十分なのでいい加減追加したいなと考えています。
余談
API をいい感じに追加しようと思って設計とかまじめに考えてやってみたのですが、気軽に 1000 行ぐらいになってしまってやはりこの手の機能をちゃんとレイヤーを分割してコードを書くと結構しんどい。
おわりに
なんかこうしたらいいんじゃないかみたいなことがあれば教えてくださいな。
MySQL を使った最高に頭の悪いポートフォリオを作った話
はじめに
JVM オプションをいい感じに比較してくれるサービスを作ったが、サブドメインに割り当ててしまったので大元の lrf141.dev に何もないという状況はあれだなと思い半年ぐらい前に作った頭の悪いポートフォリオサイトを作ったのでまとめる。
技術スタック
- Go 1.14
- React 16.13.1
- MySQL 8.0.21
- Redis 6.0.5
- Docker
作ったもの



画面はこんな感じ。どこかでみたことのある画面ですね?
portfolio データベースが存在し、そこにあるテーブルをいい感じに select * from で呼び出すとテーブルのフォーマットのまま表示してくれる。
ポイントはテーブルのフォーマットのまま表示してくれるというところ。
仕組み
Go + Gin で Web バックエンドを作り、フロントエンドは React で作っている。
ここで何が起こっているかというと、SQL をターミナルに入力するとそれを API に飛ばし、API は MySQL の docker コンテナに対して mysql コマンドを実行し
標準出力をアタッチしてそれをレスポンスとして返却している。そのためテーブルのフォーマットで表示されるようになる。
自分は web デザインが苦手なので、この形式であれば css とか描かなくても秩序のあるスタイルで表示してくれるので楽だった。
この時点で非常に頭が悪い。
もっと頭の悪いことは、なんでこんな形にしたかというとポートフォリオサイトをまともに更新したためしがなかったのでマイグレーションを走らせればいい感じにサイトを更新してくれる上に楽という発想。
絶望的に頭が悪い。
技術的な話
docker コンテナに対して何かを実行させる
API がコールされた段階で docker コンテナに対してコマンドを投げるがここは Go で作ったので moby を使っている。
結構便利でコマンドも投げられるし、コンテナ内の標準出力をアタッチする API も用意されていてこれだけでどうにかなった。
Docker Engine API を呼び出しているらしく、この辺りを使えばもっと面白いこともできる。
Redis を使ったキャッシュ
テーブルが3,4つしかないので毎度コンテナに叩きにいかないで同じクエリであれば redis にキャッシュされてるデータを引っ張るようになっている。Redis は最高。
MySQL User の権限を絞る
クエリが投げつけられてなんでも実行されると平気な顔をして破綻するからユーザの権限を絞っている。
CREATE DATABASE IF NOT EXISTS `portfolio`; GRANT SELECT ON `portfolio`.* TO 'portfolio'@'%'; FLUSH PRIVILEGES;
こんな感じの設定をいくつか追加している。
おわりに
何かまずいところあったら教えてくださいな。
Springboot アプリケーションのデプロイ準備を考える
はじめに
最近趣味で Springboot アプリケーションを作っていてデプロイ準備が地味に面倒だったので備忘録としてまとめる。
いくつかうまくいかなかった方法があるので、ここではうまく行った方法をまとめていく。
準備すること
環境別の properties を用意する
Redis や MySQL を利用している場合、開発環境と本番環境で異なる設定を利用したい場合がある。
この時 gradle のタスクとして切り出して、それぞれの環境に適用するべき properties ファイルを生成することが出来るがもう少し手抜きをする。
以下のようなディレクトリ構成で spring.profiles.active オプションで環境別の設定を利用することができる。
./src/main
├── java
│ └── net
└── resources
├── application-dev.properties
├── application-prod.properties
├── public
└── templates具体的には -Dspring.profile.active=dev だと application-dev.properties が読み込まれるようになる。
この設定を前提にする場合は、各環境毎のプロパティファイルを用意しておくだけでよい。
dev 環境を整える
普段、開発環境では Springboot を手元で立ち上げていて、アプリケーションで利用するミドルウェア群は docker-compose を使って用意したコンテナを利用している。
そのため開発環境で Springboot を立ち上げる時の設定を若干手を加える必要がある。
普段は bootRun を使用しているので bootRun の設定を以下のように書き換える。
bootRun {
args = ["--spring.profiles.active=dev"]
}これで常に dev 環境用のプロパティファイルを ./gradlew bootRun 実行時に読み込める。
jar と resources を固める
単純に ./gradlew build の成果物である build/libs/*.jar と build/resources を tar に固めてどこかに置いておくだけ。
これは github action を使っていい感じにまとめる。
以下の yaml でよろしくやってくれる。
name: Create Application archive on: push: branches: [ main ] pull_request: branches: [ main ] jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - uses: actions/setup-java@v1 with: java-version: '11' # The JDK version to make available on the path. java-package: jdk # (jre, jdk, or jdk+fx) - defaults to jdk architecture: x64 # (x64 or x86) - defaults to x64 - name: Setup npm uses: actions/setup-node@v1 with: node-version: 14.x - run: cd ./frontend && npm i && npm run build && npm run postbuild - name: Grant execute permission for gradlew run: chmod +x gradlew - name: Build with Gradle run: ./gradlew build - name: Create Archive run: | mkdir archive cp ./build/libs/jvm-*.jar ./archive/jvm.jar cp -R ./build/resources ./archive/resources tar czvf archive.tar.gz archive/ - uses: actions/upload-artifact@v2 with: name: archive path: ./archive.tar.gz
番外編: redis でちょっとハマった
docker-compose で java, redis をいい感じにデプロイしようとしたらこけた。
この時の原因は参照している properties ファイルが異なることだった。
ここの準備を終えるまで環境別の properties ファイルを用意してなかったが、それが面倒なのであれば redis のコネクションドライバをコード内で上書きしてしまうのが楽だった。
結局この記事でやったことが適用できたので特にそういったことをする必要はなくなった。
おわりに
アーカイブ作ったり、環境別の設定をいい感じにする方法はわかったのでデプロイを自動化したい
2020 年を振り返って
はじめに
仕事納めなる概念が降って湧いてきたにさっき気がついたので一足先に今年の振り返りを。(仕事納めは28日)
ずっと取っていなかった夏休みを23から取っているので気分は年末です。
会社がどうとか言うのはあまり書くつもりがなく、一年経った時にでも気が向いたら書こうかなと思っている。あくまでもエンジニアとして今年どうだったかとかを中心に書きたい。
今年の総括
仕事忙しかった
これに尽きる。自社サービスかつメンテフェーズになっているプロダクト・ミドルウェアに関わっているので工数ヤベェとかもあんま無いと聞いていたので暇なのかなーって思っていたけどそんなことはなかった。先輩がごついプロジェクトやっている間にプロダクトのバックログ捌いたりとか結構あった。兼務が多いチームだけど専任でやっているので大手を振って工数使っていた。ので、忙しい時はまじで忙しかった。
あとは別プロダクトの新機能開発に関わったり、認証周りみたり、障害起こしてデグレしたりとかまぁ結構いろんなイベントがあった。これもなかなかにタスクの進捗が悪い時に重なると忙しさの元凶となっていた。
それ以外だと、弊社ではモブプロが主流になっているところ多いけど完全に個人作業で拾ったタスクを捌いては拾って捌いては拾ってを繰り返していたので気が抜けるところあんまりなかった。
忙しいには忙しいけど、自分の本部の中でもベテラン勢が集まっているところなので仕事は楽しかった。鋭いレビューを頂いたり、しっかり面倒みてもらったり。レベルアップしているなっていう実感があったのでとても良い。
インプット多かった
これはまじで多かった。
複数製品の基盤になっていたり、それぞれの設定を持っていたりしているプロダクトに関わっている + 個人作業だとかなり学ぶ必要のあることが多かった。
基本的には Java なんだけど、フロントエンドもやったりミドルウェア周りみたり認証周りみたりとめちゃくちゃ多岐に渡るなというのが感想。
- Java, Jetty, SpringBoot
- Javascript, Closure Library, TypeScript, React
- MySQL, Elasticsearch, Gorush, FCM, Docker
- SAML, 2FA, TOTP
このあたりを結構がっつりみた感じある。これ結構理解しながらやるのは大変だった。
それ以外だとスプリントレビューとかリファイメントとかのお作法だったり、タスク管理、試験、CI周り、デプロイ、障害対応のイロハ、本番環境(正確には本番環境のバックアップ)の歩き方とかこれもこれで理解しなきゃいけないことがたくさんあって大変だった。
あんまりアウトプットできなかった
こんだけインプットしているとアウトプットが全然できなかった。
強いて言えばこの辺りとか。
speakerdeck.com
この辺りぐらいかなと言う感じ
github.com
ブログも全然更新できていないしな。
責任を痛感する一年でもあった
これは地味だけど確実に刺さってくるもので、自分の決断が製品に影響すると思うと結構責任あるなぁと痛感した。特に何か追加しようとした時のシステムアーキテクチャとか、工数はかかるがやらねばならぬこととか。何をどう判断するか、そのあたり結構くるものがあった一年だった。割と慣れてきたけど。
どこを目指していたんだ俺は。
色々やらんといけないこと、わからないといけないことはその都度捌いてきたけど、これ書いてて思った、今年の目標ってなかったなと。何を目指して今年エンジニアやってきたんだろうと。
来年はなんか細かく目標立ててやっていきたいなとは思うが何を目指そうかというところ。まぁゆっくり探しますか。
その他・雑感
よく言われているやつ
基本在宅だった。途中、感染者数が二桁前半の時とか出社してたけど基本家。UberEats が捗る一年だった。満員電車も全然乗らなかったし。 ただし諸々の健康には悪いなという感想しかない。
知り合いあんまり増えなかった
リモートで働けるのまぁ楽だなって思っていたんだけどその後の配属先とかの関係で全然知り合いが増えないなという思いがあった。やっぱりリアルで会わないと家で仕事して1日が終わり、1ヶ月が終わり、気がつけば1年が終わろうとしていた。あと基本的にチーム以外で話をすることがなくなった。
会社の部活動なるものに参加した
知り合い増えないのやばいなと思って会社の部活動(オンライン開催)に顔を出してみた。エンジニア以外の方と接するのが久々すぎて何話せばいいかわからんかった。けど、そういった気持ちになるのも久々で楽しかった。そこからたびたび参加している。良い。
会社の同期、先輩とちょくちょく出かけた
これが社会人かという感じ。総じて楽しかった。
まとめ
今年は色々レベルアップしたなぁと思うこと多いけど、なんのためにレベルアップしてきたのかと思うこともあるので来年はなんか目標持ちたいとこれ書いてて思った。
人生の進捗は虚無です。
JIT コンパイラのコンパイラスレッド、コード最適化について
はじめに
今回は前回の内容に引き続きJIT コンパイラについての話。割と薄くなる予定。
コンパイラスレッドとか最適化とかそのあたり。
Java パフォーマンスには、 JVM エンジニアが JVM の振る舞いを検証するために利用したり、コンパイルに興味を持った人が読むと良いとある。
コンパイラのスレッド
前回の記事で、コンパイルには閾値があると書いたがそれに関連している。
JVM ではコンパイル対象になったメソッドやループはキューに配置され、バックグラウンドで動く一つ以上のスレッドによって非同期プロセスとしてコンパイルが行われる。
そのためコードを実行中であってもコンパイルすることが可能となる。
またその時に利用されるキューは FIFO ではなく、呼び出しカウンタの値が大きいメソッドが優先的に処理される。
デフォルトでは C1 コンパイラはスレッドが一つで、C2 コンパイラはスレッドを二つ利用する。
この値は -XX:CICompilerCount=N で合計数を指定することでスレッド数を制御できる。
コンパイラのスレッドは単一 CPU マシン上であれば、一つにしてしまい競合状態を減らす方がパフォーマンス的には良いとされているがそれはウォームアップ時に大きなメリットがあるだけで多くのホットスポットがコンパイルされたあとではメリットが少ない。
また階層型コンパイルを利用している環境下ではスレッド数を多くするとコンパイルスレッドも増えシステム全体に影響を及ぼす場合がある。
この時はスレッド数を減らした方がウォームアップの期間が長くなるというデメリットはあるものの全体のスループットを向上させることができる。
- XX:BackgroundCompilation を false にすると非同期的なコンパイルが走らなくなり、ブロッキングモードでコンパイルが実行される、つまりコンパイルが終わるまで処理が止まるということもできる。
あまり使わないとは思うけど。
コードの最適化
インライン化
以下のコードを考える。
public class Point { private int x, y; public int getX() { return x; } public void setX(int i) { x = i; } }
Point p = getPoint();
p.setX(p.getX() * 2);
このように呼び出されるコードがある場合、次のようにインライン化される。
Point p = getPoint();
p.x = p.x * 2;
これによりメソッド呼び出しが省略されるため、処理速度が向上する。
これまでのコードキャッシュやスレッドとは異なり、インライン化が行われる場合の振る舞いを見る術がない。
しかし、JVM をソースコードビルドするのであれば -XX:+PrintInlining というフラグを利用可能にすることもできる。
インライン化するかどうかの判断基準はメソッドがよく利用されるかどうかとそれ自体のサイズに大きく影響される。
そのため、 -XX:MaxFreqInlineSIze, -XX:MaxInlineSize でインライン化するメソッドのサイズを調整することもできる。
エスケープ分析
次はエスケープ分析について。
これはデフォルトで有効になっていて、これが利用できる場合は積極的に最適化を行う。
最適化を行う項目はいろいろとあるらしいが、書籍に書かれているものであればループ内でのみ特定のオブジェクトが利用されている場合
同期ロックを取らないようにしたり、フィールドの値をメモリに持つ必要がなければレジスタに配置したり、オブジェクト自体が各フィールドだけ管理するようになったりと様々。
これはシンプルなコードだけでなく複雑なコードに対しても同様に適用される。
最適化がうまくいかない場合は、JVM のバグであることが多いそうだが、一番簡単で効果のある対処法として対象のコードをシンプルにすることが有効らしい。
JIT コンパイラのコードキャッシュ
はじめに
前回は JIT コンパイラの基礎について触れたので、今回は JIT コンパイラのコードキャッシュとそのチューニングついて。
基本的なものだと、どちらのコンパイラを選択するか、階層コンパイルを利用するかどうかがあるらしいが
もう少し踏み込んだ内容について書いていく。
今回も例によって Java パフォーマンスを参考文献にしている。
コードキャッシュとそのチューニング
コードキャッシュとは
コードキャッシュとは JVM がコードをコンパイルすることによって生成されたネイティブコードを持っている領域のことで Java 9 以降ではコードヒープと呼ばれている。
この領域を圧迫すると、一部のホットスポットだけコンパイルが適用され、その他の部分はインタープリターで実行される or コンパイル適用を一旦破棄するなど性能に大きな影響を及ぼす。
コードキャッシュの確認
- XX:+PrintCodeCache オプションをつけることで確認できる。
❯ java -XX:+PrintCodeCache -version
openjdk version "11.0.8" 2020-07-14 LTS
OpenJDK Runtime Environment Corretto-11.0.8.10.1 (build 11.0.8+10-LTS)
OpenJDK 64-Bit Server VM Corretto-11.0.8.10.1 (build 11.0.8+10-LTS, mixed mode)
CodeHeap 'non-profiled nmethods': size=120032Kb used=15Kb max_used=15Kb free=120016Kb
bounds [0x0000000126cd2000, 0x0000000126f42000, 0x000000012e20a000]
CodeHeap 'profiled nmethods': size=120028Kb used=97Kb max_used=97Kb free=119931Kb
bounds [0x000000011f79b000, 0x000000011fa0b000, 0x0000000126cd2000]
CodeHeap 'non-nmethods': size=5700Kb used=972Kb max_used=977Kb free=4728Kb
bounds [0x000000011f20a000, 0x000000011f47a000, 0x000000011f79b000]
total_blobs=299 nmethods=71 adapters=141
compilation: enabled
stopped_count=0, restarted_count=0
full_count=0CodeHeap の種類は 3 つあり
- non-profiled nmethods
- profiled nmethods
- non-nmethods
と分かれている*1
これらを合計しておおよそ 240MB の領域が割り当てられている。
コードキャッシュが圧迫された場合の挙動
このコードキャッシュ(コードヒープ)の挙動で重要となるのは、コードキャッシュが圧迫された場合の挙動で、コンパイルしたネイティブコードをコードキャッシュに配置できなくなると JIT コンパイルを停止する。この時、コードキャッシュがいっぱいになったというログメッセージが出力される。
コードキャッシュにネイティブコードを配置できなくなると JVM は一度最適化したネイティブコードを破棄し、Java のプログラムを実行する際に設定されている最低量のコードキャッシュを確保しようとする。*2
それらの処理が完了した段階で JIT コンパイルを再開する。
単純なチューニング
これらからわかるようにコードキャッシュのことを考慮した場合、重要となるのはコードキャッシュの上限サイズとなる。
上限サイズをどのように設定すればよいといった定量的な基準はなく場当たり的に設定する必要が出てくる。*3
コンパイル時の基準
コードキャッシュ自体のチューニングと言うとサイズを調整するぐらいしか見当たらないが、JIT コンパイルの特性を知る事で間接的にパフォーマンスに影響を与えることができる。
そのうちの一つがどのタイミングでコンパイルが行われるかということを明示的に指定する方法。
前回は JIT コンパイルで C1, C2 コンパイラについてまとめたが、それらがどう言った基準で適用されているかについて知り、それを設定することでコードキャッシュを有効活用できる場合がある。
JIT コンパイル時は呼び出しカウンタとバックエッジカウンタの二つを JVM が記録しておりこの総和が閾値を超えた段階で JIT コンパイルが適用される。
呼び出しカウンタはそのままの意味だが、バックエッジカウンタとはメソッド内のループ内で処理が完了した回数を示している。
やたら複雑で巨大なメソッドを実行する場合 JVM はメソッドの終了を待つ事なくコンパイルを実行するケースがある。その時はバッグエッジカウンタが個別の閾値を超えるとメソッド全体ではなく該当するループ処理がコンパイル対象となる。
こういったコンパイルを OSR *4*5 と呼ぶ。
ここまで長々とまとめたがカウンタについては -XX:CompileThreshold でどれだけその値を変更することができる。デフォルトでは C1 コンパイラが 1500, C2 コンパイラが 10000 と設定されている。
コンパイルプロセスを理解する
コードキャッシュと密接な関わりがある JIT コンパイルを理解することはチューニングとは直接関係しないが大事なことなのでまとめる。
前回も行った -XX:PrintCompilation フラグを利用して JIT コンパイルの挙動を知るという操作。これについてもう少し解説する。
次のログを参考にする。
460 902 3 com.sun.tools.javac.comp.Flow$BaseAnalyzer::scan (27 bytes)
460 903 3 com.sun.tools.javac.code.Types::isSignaturePolymorphic (111 bytes)
462 904 3 com.sun.tools.javac.tree.JCTree::pos (2 bytes)
462 906 3 com.sun.tools.javac.tree.JCTree::hasTag (14 bytes)
462 907 3 com.sun.tools.javac.code.Type$ClassType::accept (9 bytes)
462 905 1 com.sun.tools.javac.code.Type$JCPrimitiveType::isPrimitive (2 bytes)
463 225 ! 3 jdk.internal.jimage.BasicImageReader::slice (32 bytes) made not entrant
464 663 4 java.util.HashMap::put (13 bytes)
464 908 3 java.lang.invoke.DirectMethodHandle::make (263 bytes)
464 96 3 java.util.HashMap::put (13 bytes) made not entrant
465 736 4 java.lang.String::toString (2 bytes)
465 472 3 java.lang.String::toString (2 bytes) made not entrant
465 910 3 java.lang.invoke.MethodHandles$Lookup::<init> (15 bytes)
465 909 3 java.lang.invoke.MemberName::isField (7 bytes)
465 911 3 java.util.ArrayList::isEmpty (13 bytes)
466 912 3 com.sun.tools.javac.jvm.Code::typecode (141 bytes)
467 913 3 com.sun.tools.javac.jvm.Code::width (42 bytes)
467 914 3 com.sun.tools.javac.jvm.Code::width (16 bytes)
467 915 3 com.sun.tools.javac.code.Type::typeNoMetadata (19 bytes)
468 713 4 java.lang.StringLatin1::indexOf (121 bytes) made not entrant
470 916 % 3 SampleAlgorithm::main @ 15 (65 bytes)
470 917 3 SampleAlgorithm::main (65 bytes)
470 918 % 4 SampleAlgorithm::main @ 15 (65 bytes)
472 916 % 3 SampleAlgorithm::main @ 15 (65 bytes) made not entrant
672 918 % 4 SampleAlgorithm::main @ 15 (65 bytes) made not entrantまず重要なこととしてこのログは以下のフォーマットを取る。
タイムスタンプ コンパイルID 属性 階層型コンパイルレベル メソッド名 サイズ 非最適化
コンパイルレベルに関しては前回の通りなので省略。
タイムスタンプは JVM が起動してからコンパイルが完了するまでの相対的な時間を示している。
コンパイルID は内部的な ID で単調増加するが C2 コンパイラや、非同期処理が利用されると必ずしも昇順になるとは限らない。
属性はコンパイルされるコードの属性を示していて以下の通り
残りで重要なものは非最適化についての記述。
これには made not entrant, made zombie があるがここではまとめない。次の記事でまとめる。
ここにはないがコンパイラログにはコードキャッシュがいっぱいになったことや、コンパイル中に対象クラスが変更されたため再コンパイルが行われることなどが出力される場合もある。
これらログから想定されたコンパイルが行われているかなどの確認が可能なので、性能に思うところがあればみる事がおすすめされる。
非最適化について
PrintCompilation で非最適化される場合の挙動について。
非最適化とはすでに行われて完了している最適化をもとの状態に戻すことで、次の二つのパターンで非最適化が行われる。
entrant ではないコード
entrant *6ではないコードは非最適化の対象となる。
これが発生する原因はクラスとインターフェースの仕組みに起因するものと、階層型コンパイルに起因するものがある。
まずインターフェースに起因する場合。
次のような実装を考える。
HogeRepository repository; String param = request.getParameter("hoge"); if (param != null && param.equals("hoge")) { repository = new HogeRepositoryImpl(); } else { repository = new HogeLogger(); }
このように特定のパラメータか何かに強く依存し、インターフェースのインスタンスが異なる場合 param が hoge を取り続け C2 コンパイルが適用されると repository の型が HogeRepositoryImpl だと判断される場合がある。
そうなった場合、 else の処理が何らかの原因で呼ばれ続けると最適化した型情報が変わるため entrant なコードとして非最適化する必要が出てくる。
次に階層型コンパイルが起因となる場合について。
階層型コンパイルでは C1 コンパイルが適用され、その後 C2 コンパイルが行われる場合がある。
この時 C2 コンパイルが行われ利用できる状態になったら JVM は C1 コンパイルの結果であるコードを置き換える必要があり、置き換える対象となるクラスに印的なものとして made not entrant をつける。
おわりに
次はコンパイラスレッドとかについてまとめる。
参考文献
- https://www.oracle.com/webfolder/technetwork/jp/javamagazine/Java-JA13-Architect-evans.pdf
- nmethod クラス関連のクラス (ExceptionCache, PcDescCache, nmethod, nmethodLocker, 及びそれらの補助クラス(DetectScavengeRoot, VerifyOopsClosure, DebugScavengeRoot)) http://hsmemo.github.io/articles/no14LXQg07.html
- 4 コンパイル最適化(リリース2) https://docs.oracle.com/javacomponents/jp/jrockit-hotspot/migration-guide/comp-opt.htm
- Javaの謎のパフォーマンス劣化現象との戦い - Cybozu Inside Out | サイボウズエンジニアのブログ https://blog.cybozu.io/entry/2016/04/13/080000
- 15 Codecache Tuning (Release 8) https://docs.oracle.com/javase/8/embedded/develop-apps-platforms/codecache.htm