Tuple を実装する
この記事は「けんつの1人 DBMS アドベントカレンダー Advent Calendar 2019 - Adventar」 12 日目の記事です。
はじめに
どうも、最近バイトに卒研にアドカレと目を酷使しまくっていつも目が充血しているけんつです。眼球ってどうやって休ませたらいいんでしょうか。
そろそろ結構勉強だけという状況に飽きてきたので、ストレージから実装していきます。
まずは Tuple です。
行を表現するため本来であれば色々考慮する必要がありますが、比較的妥協を重ねてシンプルにしています。
実装
といっても、github で Pull Request を作りながら開発しているのでそちらを見ると全体像が見えてきます。
なのでここでは実装していて色々と考えたこと、妥協したことなどまとめます。
タプルの構成
Tuple は次の様に構成されます。
| name | length |
| Magic Number | 2byte |
| MinTxId | 8byte |
| MaxTxId | 8byte |
| Len | 2byte |
| Tuple Body | var-length |
| total | 128byte |
Tuple Body
| name | length |
| Magic Number | 2byte |
| Data Type | 2byte |
| Data Size | 4byte |
| Data | var-length |
コード上では以下の通りです。
type Tuple struct { Magic uint16 MinTxId uint64 MaxTxId uint64 Len uint16 Body [TupleBodySize]TupleData // TODO: fix length } type TupleData struct { Magic uint16 Type uint16 Size uint32 Number int32 String_ string }
先行事例では、この部分は Protocol Buffer を使用していましたが、 TableSpace などでまとめて管理したい場合に
Protocol Buffer にまかせてしまうとかゆいところに手が届かなかったので
バイナリへのシリアライズは自作して byte 列に直しています。
gob をつかえばよいという声もあるかもしれませんが、あれはバイナリを構造体に変換するための情報もバイナリにシリアライズされるため 128 byte という固定長が困難と判断して使用しませんでした。
データ型の扱い
今回、自作する DBMS では int32 相当の int 型と varchar or text 相当の string 型があります。
これらは interface{} 型で扱ってしまうと gob を使うしかバイナリにシリアライズする方法がなくなってしまうので
TupleData 構造体でデータ型の分だけ専用にフィールドを持っています。
CMU の講義内では浮動小数点数の記載もありますがあれを実現しようとすると IEE754 あたりに準拠させる必要があるので今回はシンプルに実装できる文字列と整数としています。
タプルサイズ問題
これは完全に妥協点です。
タプルを固定長にしたせいで、構造体⇔バイナリの変換が複雑になってしまったために実際に保持できるデータは 70 ~ 80 byte 程しかないはずです。
これは明日まとめる Page の構成に大きく関係しているのでその時にまたまとめますが、1 Page = 16 KB という容量制限を確実に設けるために妥協しました。
おわりに
今回は複雑な処理の割にシンプルなタプルになったのでここまでです。
明日はページについて書きます。
ストレージ周りの設計を考える
この記事は「 けんつの1人 DBMS アドベントカレンダー Advent Calendar 2019 - Adventar 」 11日目の記事です。
はじめに
どうも、最近書き溜めた記事がなくなってきてエクストリーム開発になりそうであせっているけんつです。
今日はとりあえず、雑にストレージの全体構造を考えてみようかなと思っています。
詳細は、それぞれ実装した記事で書くのでかなり短くなりそう。
ストレージの設計を考える
ひとまずデータベースストレージから作っていくことにしたのでザッと設計を考えていく。
ただあくまでもこうやって実装したいなという目安なので今後変更する部分はありそう。
実装する DBMS の仕様
まず先に大まかな仕様から考える。
今回は次のような限定的な仕様とする。
ストレージの全体像を考える

現状は次のように実装することを考える。
メモリ上の処理
今のところはメモリ上に置くものはバッファプールのみとしている。
これが同時実行制御を考慮し始め MySQL のような更新型を取る場合はチェンジバッファや、ロックも Two-Phase Locking などを採用する場合は
それ単体では ACID 特性を満たすのに不十分なことからログバッファを追加して、 WAL を実装する可能性も考慮している。
また図中にはないがこのバッファプールには、インデックスを保持する領域も存在している。
ディスク上の処理
基本的にデータを最大 16 KB のページとして保持することを考える。テーブルはページをひとつ以上保持することで実現する。
またテーブルには 128 byte が上限のタプルを 127 個最大で配置する。*1
ページはバイナリにシリアライズして保持するが、それは Protocol Buffer を利用するのではなく気合で byte 列にすることまずやってみる。
gob は事前にシリアライズをテストしていて、構造体を素直にシリアライズするとデシリアライズするために必要なデータとして 280 byte ほど容量が増えるため使用しない。
これらのディスク上に永続化する必要があるものは DiskManager のような何かを用いて行うが、出来るなら Direct I/O を使いながらやってみたい。
おわりに
これ、実はいくつかもう実装しているけど詳しいことはそれぞれのパートで書くことにする。
ここにまとめるには要素が多い。あと、DBMSってストレージがほとんどな気がしてきた。
*1:ページヘッダーを考慮するとタプルの最大数を127にする必要がありそう
BufferPool の実例を調べる
この記事は「 けんつの1人 DBMS アドベントカレンダー Advent Calendar 2019 - Adventar 」 10日目の記事です。
はじめに
どうも、最近 B Tree Index を実装しても、重複ありで範囲検索するのめっちゃ難しくない?って思い始めたけんつです。
インデックスにとりつかれている気がする。
今日は、 Buffer Pools を実装しているなかでどうやって設計すると良いのか迷ったので PostgreSQL の Buffer Pool の仕組みを追うことでもうちょい理解を深めていこうかなと思っています。
使えそうな部分を重点的に列挙していくので短くなりそうです。
Buffer Pool
参考資料↓
http://www.interdb.jp/pg/pgsql08.html
(ぽすぐれって内部仕様の詳細ドキュメントが充実してていいよね)
そもそも Buffer Pool ってなんぞというところから始めると、Buffer Pool はストレージエンジンが担保していることが多いが
ストレージ的な機能を提供するのではなく物理的なストレージのデータをメモリ上に展開したり、データが追加された際に一時的に保持するためのメモリ領域のことを指す。
言わばファイルキャッシュのようなもので、更に平たくいうなら単にキャッシュと思ってもらっても差し支えないと思う。
実際以下のような構図になっている。

ここでいうところの Backend Process とはマルチスレッドでそれぞれ動作する SQL の解析や実行計画の決定、最適化よりユーザ側の面の全てを指す。
それでは順を追ってみていく。
Buffer Pool Manager の構成
バッファプールを管理するバッファプールマネージャーはバッファテーブル、バッファディスクリプタ、バッファプールから構成されている。
このあたりの詳しい解説はこのあとまとめる。
ここでまず大事なのはバッファプールは配列であり、各スロットに 1 page が配置されるようになっているということである。そして、その配列のインデックスを buffer_id と呼ぶこと。
これが、バッファプールマネージャを通したバッファプールの扱いに関連している。
バックエンドプロセスによるバッファプールの操作

バッファプールのデータを扱う場合に、以下のプロセスを踏む。
- テーブルやインデックスを読み込む場合、バックエンドプロセスはページの buffer_tag をバッファプールマネージャに渡す。
- バッファプールマネージャは既にページがバッファプールに存在する場合はそのインデックス*1を返す。バッファプールに存在しない場合はストレージから読みだしてバッファプールに対象のページを格納した上でそのインデックスを返す。
- バックエンドプロセスは buffer_id を利用して、バッファプールにアクセスする。
データの読み込みではなく、書き込みが走った場合はそのページをダーティページ*2として認識する必要がある。
また、読み込む際に空きスロットがない場合は LRU ではなくクロックスイープを使用してスロットを開放する。
バッファプールマネージャの構造
バッファプールマネージャは以下の構造をとる。

ポイントは以下の通り。
- Buffer Pool は配列であり、各スロットにページデータを持つ。また Buffer Pool のインデックスを buffer_id という。
- Buffer Descriptor は配列であり、 Buffer Pool の buffer_id と同一の*3 buffer_id で参照できる。この Descriptor はページのメタデータを保持する。
- Buffer Table は格納された buffer_tag と、 Buffer Descriptor の buffer_id とを対応付けるハッシュテーブルとなっている
Buffer Table
バッファテーブルはハッシュ関数、ハッシュスロット、データエントリの3要素で構成されている。
ここでは、まずハッシュ関数を使って buffer_tag をハッシュスロットにマッピングする。またハッシュを使用するということは当然ハッシュが衝突する可能性があるがバッファテーブルはそのような状態を単方向リストを使用したチェーン方式で解決する。
具体的に何をするかというと、以下の図がわかりやすい。

このように、同じハッシュスロットを用いる場合、それらを単方向リストとして表現する。
データエントリはページのバッファタグと、メタデータを持つ buffer_id の2つから構成されている。
Buffer Descriptor
バッファディスクリプタはページのメタデータを保持している。PostgreSQL では次のフィールドから構成される。
- tag: Buffer Tag を持つ
- buffer_id: 前述の通り
- refcount: ディスクリプタが示すページに現在アクセスしているプロセスの数を示す。 Pin Count とも言われる。この数値が 0 よりも大きければページは固定*4され、そうでないならページの固定は解除される。*5
- usage_count: これはアクセスされた回数。この回数をクロックスイープで使用する。
- context_lock, io_in_progress_lock: おそらく排他制御、軽量ロックと書かれているのでラッチに近い機能をもっていると考えられる。*6
- dirty bit :ページがダーティページかどうかを示す
- valid bit :保存されたページが読み取り、書き込みが可能かどうかを示す。
- io_in_progress bit : 関連するページをストレージから読み書きするかどうかを示す。
基本的にロックやラッチに関わる値を保持している。
番外編 MySQL の Buffer Pools
ここにもあるし、前にもどこかでまとめた記憶があるが LRU キャッシュとなっている。
バッファプールを 5/8, 3/5 に分割してそれぞれをサブリストとすることで二度目以降の使用がないデータを優先的に開放するようになっている。
ただこれ以上詳細な情報がなかったので、どういったフィールドを保持していてどのようにロックやラッチを使っているかというところまではわからない。
まとめ
参考文献を使った章以降は、基本的にそのバッファプールマネージャの構造においてどのようにページを開放するかなどなので説明を省略した。
InnoDB におけるページとインデックスの物理的な構成について
この記事は「 けんつの1人 DBMS アドベントカレンダー Advent Calendar 2019 - Adventar 」 9日目の記事です。
はじめに
どうも、最近このアドカレが本当に終わるのかどうなのか心配になってきているけんつです。
今回は DBMS のストレージ構造を考えていたらインデックスを物理的に保存する場合の構造ってどうなってるんだろうなぁと思ったので InnoDB の内部構造とその物理的な形式を追っていく。
あんまり深く追ってしまうと本当にキリが無いので自分の理解が足りない部分をメモしていく感じになる
参考にしたサイト
InnoDB のスペースファイルレイアウト
InnoDB のデータストレージモデルは MySQL のドキュメントではテーブルスペースと呼ばれているが InnoDB 自体ではファイルスペースと呼ばれている。
スペースは ibdata1, ibdata2, ... などで複数の物理ファイルで構成されるが単一の論理ファイルとして扱われる。
InnoDB の書くスペースには 32bit のスペースIDが与えられる。このIDを元に DBMS やストレージはスペースを参照する。
またこの ID は 0 から始まり、ID が 0 のものはシステムスペースと言われる。このシステムスペースはストレージに関する内部的な情報を保持する。
ページ構成
各スペースは 16 KB*1 毎に 32 bit のID が割り当てられページに分割される。
このページ ID はスペースの先頭からのオフセットに過ぎない。
実際にページは次のようなレイアウトを取る。


FIL Header *2というものが 38 byte あり、ボディに相当する部分が 16338 KB ある。
そして末尾に FIL Trailer というものが 8 byte ある。
Header はページの種類を示すために使用される。
FIL Header
| name | length |
| Checksum | 4 byte |
| Offset (Page Number) | 4 byte |
| Previous Page | 4 byte |
| Next Page | 4 byte |
| LSN for last page modification | 8 byte |
| Page Type | 2 byte |
| Flush LSN (0 except space 0 page 0) | 8 byte |
| Space ID | 4 byte |
FIL Trailer
| name | length |
| Old-Style Checksum | 4 byte |
| Low 32 bits of LSN | 4 byte |
Header, Trailer の構造的特徴
まずページタイプはヘッダーに保存される。このヘッダーには後に続くページデータを解析するために必要な情報が入っている。またスペースIDもヘッダーに直接保存されている。
ページは初期化される段階でページIDをヘッダーに保存する。そして、フィールドから読み取られたページIDがファイルへのオフセットに基づいていることを確認する。
また Previous Page と Next Page というフィールドが存在するように、ページは前後のページに対するポインタを保持している。
これによりページは双方向リストとして扱うことができる。インデックスの構築はこの特性を利用した上で全てのページをリンクすることを目的としている。
スペースファイル
スペースファイルは多くのページの連続体となっている。ただ連続しているわけではなく、効率的に管理するためにページは64個で1グループと見なされエクステントという単位で管理されるされている。このエクステントを連続して保持しているのがスペースファイルとなる。
そのためは次のような構造を取る。


おわりに
インデックス全然わからない。
既存の RDBMS のストレージがどのような仕組みになっているのか調べてみる
この記事は「 けんつの1人 DBMS アドベントカレンダー Advent Calendar 2019 - Adventar 」 8日目の記事です。
ここまで勉強してみて
ここまで CMU Database Systems を追ってきて、ストレージ周りという意味では一段落したのかなと思っている。
ただここで気になったのが既存の RDBMS のストレージ周り、いわゆるストレージエンジンは実際にはどういった実装がされているのかということ。
なので今回はそれを調べて色々とまとめていく。
InnoDB を追っていく。
特に使えるからという理由でなく、なんとなく MySQL が好きなので MySQL のデフォルトストレージエンジンである InnoDB を対象に追ってみる。
といっても、何をどう追えばいいのかわからなかったので適当に「InnoDB Internal」 みたいなぐぐり方をして出てきたものを足がかりに調べてみる。
InnoDB のアーキテクチャ
ここでは MySQL 8.0 で使われている InnoDB を対象にまとめてみる。

この画像にあるなかで、今回やっている内容に関係しそうなものと言えば
メモリに配置されるものであれば
- Adaptive Hash Index
- Buffer Pool
ディスクに配置されるもので
- Tablespace
あたりとなる。
OS Cache についてもまとめる必要がありそう。
Adaptive Hash Index
これはトランザクション機能や信頼性を犠牲にすることなく、ワークロードとバッファプールに十分なメモリをもたせたシステムで、オンメモリデータベースのような機能をもつ。
頻繁にアクセスされるインデックスのページに応じてメモリ内に構築されるハッシュインデックスで、キーに対する値を取得する際に使用される。
MySQL 5.6 における Adaptive Hash Index にはなってしまうが次のドキュメントに B+ Tree と Hash Index の比較が書かれている。
MySQL :: MySQL 5.6 リファレンスマニュアル :: 8.3.8 B ツリーインデックスとハッシュインデックスの比較
Buffer Pool
これは InnoDB にアクセスが行く前に構えているテーブルとインデックス情報をキャッシュするメモリ上の領域を指す。
データそのものにアクセスする際にこれにキャッシュされているとメモリ上の値を直接使用することができるため処理の高速化が予想できる。
また面白いことに、このバッファプールは通常単方向リストとして実装されることが多いが
そのバッファプールリストは2つのサブリストからなり、バッファプールが使用できる領域の 5/8 が比較的直近のデータが格納される領域となっていて
残り 3/8 が比較的古いデータが保持される構造になっている。
こうなっているのは、まずページが読み込まれた時に比較的古いデータが保持されるリストの先頭に追加される。
古いデータを保持するバッファプールリストの要素が読み込まれた場合、それは新しいデータを保持するリストに移動する。
この様にして効率よくメモリを利用する仕組みが取られている。
バッファプールは LRU に基づいて開放される。
MySQL :: MySQL 8.0 Reference Manual :: 15.5.1 Buffer Pool
ざっとみた感じでは CMU Database Systems で紹介されていたものと似ている。
Table Space
これは Database Storage の時にやった内容とは少し異なる方法で実装されている。
そもそもにこれは何かというと実際には、これがデータを保持しているということになっているらしいが、次のような構成を取っている。
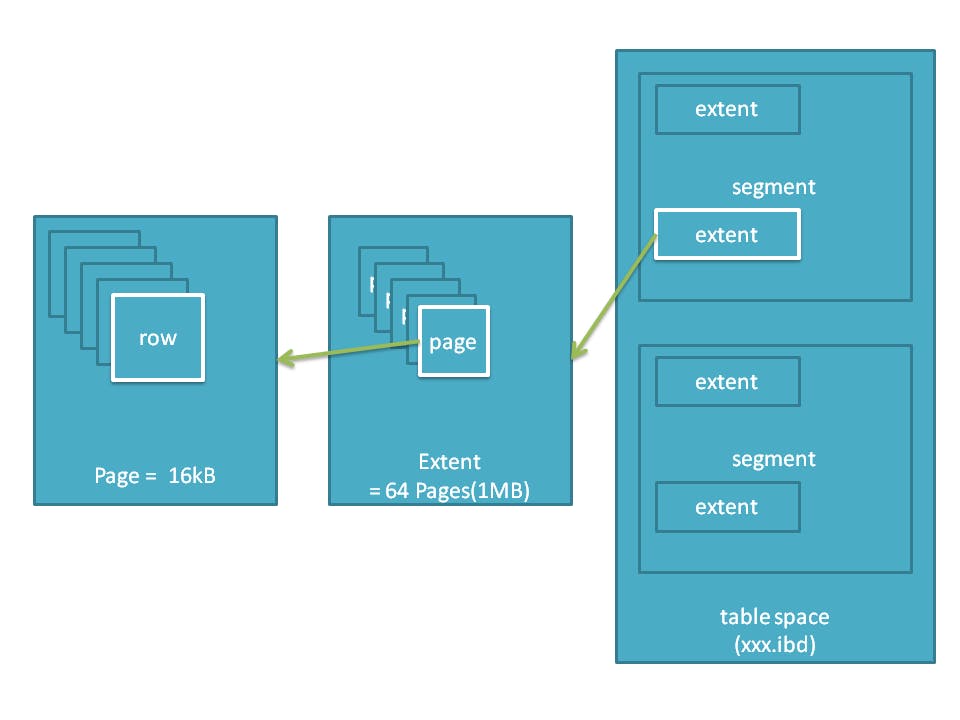
基礎MySQL ~その 5~ InnoDB② - Qiita
テーブルスペース*1の中にセグメントという領域があり、さらにその中に extent という領域*2が存在し
その extent の中にみんな大好き Page *3が格納されている。
テーブルスペースといっても、様々でその中でも特に関係のあるものといえば「File-Per-Table Tablespaces」だと思う。
これを有効にしない状態でデータを書き込むと ibdata が肥大化するなどの懸念があるが、これを有効にすることでテーブル毎にテーブルスペースを独立させることができるため単一ファイルの肥大化を防ぐことができる。
OS Cache と Database Storage
通常、Linux 環境下でファイルにアクセスする場合ファイルキャッシュを経由する。ファイルキャッシュは本来、同一ファイルの読み込み等が行われた際にそれを通すことで読み取りを高速化したり
遅延書き込み機能を使うことでプロセスに対する書き込み性能を向上させる役割がある。
しかし、ほとんどの DBMS にはバッファプールが存在するためファイルキャッシュを経由するとキャッシュを実質的に2つ経由することになり無駄な遅延が発生する。
そのため、 ファイルキャッシュを利用しない Direct I/O という機能*4を使い余分なキャッシュを経由せずにデータをファイルとして扱うようにしている。
これは InnoDB にも搭載されている機能である。
CMU Database Systems をひたすら追っていく ~09 Index Concurrency Control ~
この記事は「 けんつの1人 DBMS アドベントカレンダー Advent Calendar 2019 - Adventar 」 7日目の記事です。
はじめに
どうも、最近このアドカレの一週間分をみてこれあと二週間半分やるのかと思うとすごく辛い気持ちになっているケンツです。
今回はインデックス、つまりここでは B+ Tree の同時実行制御についてやっていきます。
Index Concurrency Control
同時実行制御プロトコルは共有オブジェクトでの同時操作において正しい結果を確保するために DBMS が使用する方法を指す。
ここで言う「正しい」とは主に2つの意味合いがあり、
- 論理的正確性: 表示されるはずのデータを表示できるかどうか。スレッドが読み取りを許可する必要のある値を読み取ることが出来るかどうかに関わってくる。
- 物理的正確性: オブジェクトの内部表現が適切かどうか。データ構造内にスレッドが向こうなメモリ位置を読み取るポインタが存在しないことに関わってくる。
ここでは論理的正確性に重点を置いて進めていく。
Locks vs Latches
以前にもどこかで書いた記憶があるけど、ロックとラッチの話。インデックスにおけるロックやラッチの話なので再度ここにまとめおく。
Lock
Latches Crabbing/Coupling
Crabbing / Coupling*1 は複数のスレッドが同時に B+ Tree にアクセス/変更を許可するための決まりのこと。
次のような手順を取る。
- 親のラッチを取得する
- 子のラッチを取得する
- 安全に操作できる場合は、親のラッチを解除する。
ここでいう安全に操作できる場合とは更新時にノードの分割が行われたり、マージされない状態を指す。
基本的なラッチの手順として更に細かく見ていく。
- 検索: ルートから開始して下に移動し、子のラッチを確保してから親のラッチを解除する
- 挿入/検索: ルートから開始して必要に応じて任意の数のラッチを取得する。その後、子をラッチを取得したら安全かどうか確認する。安全な場合は全ての親のラッチを解除する。
Improved Lock Crabbing Protocol
このように一見素晴らしく見えるラッチのプロトコルにもいくつか問題がある。というのもトランザクションが挿入・削除を行う場合排他的なラッチを取得するがこの排他的ラッチはルートから取られているというがまずい。
ルートから排他ラッチが取られている場合、その並行性は大きく制限されてしまうから。
その代わりと言っては何だが、サイズ変更が必要なマージや分割が必要になることはまれであるためトランザクションは共有ラッチををリーフノードまで取得することができる。それぞれのトランザクションはターゲットリーフノードへのパスが安全であるということを想定し、 READ ラッチを取得し、検証することができる。
仮にパス内のノードが安全で無い場合は以下の様に動作する。
Leaf Node Scans
ここまで紹介したラッチはトップダウン方式を取る。*2
しかし、それを許容すると目的のラッチが使用できないといった場合が想定できる。その場合は別のスレッドがラッチを開放するまで待機する必要がある。これによりデッドロッ具が発生しない。
しかし、リーフノードスキャンでは2つの異なる方向から*3走査されるため、デッドロックの影響を受けることがある。またインデックスラッチではデッドロックの検出、回避をサポートしないことが多い。
そのため、この問題への対処は待機しないというモードをサポートする必要がある。スレッドがリーフノードでラッチを取得しようとした場合、その操作を中止してラッチを開放し、操作を再開させる必要がある。
CMU Database Systems をひたすら追っていく ~07, 08 Tree Indexes Part 1,2~
この記事は「 けんつの1人 DBMS アドベントカレンダー Advent Calendar 2019 - Adventar 」 6日目の記事です。
はじめに
どうも、最近終わったはずの卒研に追加要求が出てきて非常にしんどい気持ちになっているけんつです。
今回は Tree Index です。
実はこれ、この記事を書き終わってから書いているのですが、この記事だけ異様に時間がかかっているので何書いてんだろうなって自分でも思ってます。
Tree Indexes
Indexes
テーブルインデックスとはテーブルの列に対するサブセットのレプリカである。
また DBMS はテーブルのコンテンツとインデックスが常に同期的されていることを保証する必要がある。
DBMS の責務は他にもあり、クエリが実行された際に適切なインデックスの利用することもその一つである。*1
一般的に要素の、つまりタプルの検索に使用されることが多いがこれにはメリットだけでなく、インデックスを多く生成すればそれだけストレージで管理する要素数が増えてしまうのでトレードオフとなる。*2
B+ Tree
インデックスを構築するにも様々なデータ構造があるが DBMS 特に RDBMS で一般的な B+ Tree を取ることを考える。
まず B+ Tree とは、データのソートを維持し、検索、追加、削除を O(log n) で行うことができる平衡探索木を指す。
また順序を維持する必要がある DBMS では大体 B+ Tree でインデックスが構成される。
B+ Tree 自体は B Tree をベースに B Link Tree の相互参照ポインタなど他の B Tree データ構造がもつ特性を合わせて実装される。
更に正確に言うのであれば、B+ Tree は次のような特性を持つ M-way Search Tree のことを指す。
- 全てのリーフ濃度の深さは同じになっている
- root 以外の内部ノードは最低でも半分以上データが入っている。
- k個のキーを保持する内部ノードは k+1 個の null でない子要素を保持する。
B+ Tree の全てのノードには、Key-Value のペアの配列が含まれる。
- すべてのノード配列はキーでソートされる
- 内部ノードの値配列には他のノードへのポインタを保持する
- リーフノード値に対する2つのアプローチとして、レコードIDとタプルデータが存在する。
B+ Tree の操作
Insert
- まずリーフである L を探索する
- ソートされた順序で L にデータを追加する
- 追加できない場合は L を L1, L2 と分割して、それぞれの要素が均等になるように再構築して中間キーをコピーする
- 内部ノードを分割する場合は、要素を均等に分配し中央のキーを親ノードにする。
Delete
- リーフ L を探索する
- エントリを削除する
- 削除後 L が含む要素数が上限値の半分より多い場合は削除を完了する
- その他の場合では隣接するリーフノードを動かすことができる場合も存在する
- 上のパターンで再構築できなかった場合は、 L と隣接ノードをマージして親を削除する
B+ Tree の設計
ノードサイズ
- B+ Tree のノードサイズはディスクの速度に依存する。可能な限り多くのタプルをノードをディスクからメモリ上に配置することを考慮する。
- ディスクの速度が遅いほどノードサイズを大きくする
- いくつかの手法ではより多くのキーに対する参照を保持するのとスキャンが遅くなることのトレードオフを考える必要がある
マージの境界線
可変長キーの扱い
- ポインタ: キーをタプルへのポインタとして保存する。(ほとんど使用されない)
- 可変長ノード: B Tree の各ノードサイズを可変にする。メモリ管理のコストが上がるためあまり使用されない
- キーマップ: ノード内の Key-Value のリストにマップするポインタの配列を含ませる。スロットページに似たアプローチを取る
ユニークでないインデックス
- 重複キー: 同じノードレイアウトを使用するが、重複キーを複数保存する
- 値リスト: それぞれのキーを一回だけ保存して一意な値リストを維持する
ノード内検索
- 線形探索: ノードの Key-Value エントリーを探索するべきキーが見つかるまでフルスキャンする。
- 二分探索: その名の通り。事前にノードがソートされている必要がある。
- 補間探索: ノード内の既知のキー値に基づいて検索の開始位置を概算する。その位置から線形探索する。これも事前にソートされている必要がある。
B+ Treeの最適化
インデックスの追加的な利用
- 暗黙的なインデックス: 殆どの DBMS で行われている様にインデックスを自動生成して主キー等に適用されるものがある
- 部分的なインデックス: テーブルのサブセットに対してインデックスを貼る。これによってインデックスそのもののサイズとそれの管理コストが減る可能性がある
- カバーインデックス: クエリを実行する上で必要な全ての属性はインデックスを利用できるため、タプルを取得する必要がない場合がある
- インデックスを含む列: インデックスのみのクエリをサポートするためにインデックスに追加の列を埋め込む。
- 関数/式インデックス: 関数、式の出力を元の値でなくキーとして保存する。そのインデックスがどういったクエリで使用できるかは DBMS が決める必要がある
スキップリスト
スキップリストは中間ノードをスキップする複数のレベルにおける追加ポイントを持つソートされた単方向リストを指す。
一般的に O(log n) で検索を行うことが出来る。これは B+ Tree 以外のインデックスを構築するためのデータ構造として利用することが出来る。
これが B+ Tree を超える点として、B+ Tree より少ないメモリで構成できる点やインサートデリートでデータ構造を再構成する必要が無い点にある。
また逆に B+ Tree と比較した場合の欠点として、ローカリティを最適化しないために、ディスク/キャッシュフレンドリーでは無い点や、双方向リストを実装しない限り逆方向への探索がコストかかるから。
おわりに
卒研やら内定者懇親会へ行ったりしていたら気がつけばこの記事を書くことに一週間も費やしてしまった。
全く理解できていないので、一周した後に加筆修正する必要がありそう。