既存の RDBMS のストレージがどのような仕組みになっているのか調べてみる
この記事は「 けんつの1人 DBMS アドベントカレンダー Advent Calendar 2019 - Adventar 」 8日目の記事です。
ここまで勉強してみて
ここまで CMU Database Systems を追ってきて、ストレージ周りという意味では一段落したのかなと思っている。
ただここで気になったのが既存の RDBMS のストレージ周り、いわゆるストレージエンジンは実際にはどういった実装がされているのかということ。
なので今回はそれを調べて色々とまとめていく。
InnoDB を追っていく。
特に使えるからという理由でなく、なんとなく MySQL が好きなので MySQL のデフォルトストレージエンジンである InnoDB を対象に追ってみる。
といっても、何をどう追えばいいのかわからなかったので適当に「InnoDB Internal」 みたいなぐぐり方をして出てきたものを足がかりに調べてみる。
InnoDB のアーキテクチャ
ここでは MySQL 8.0 で使われている InnoDB を対象にまとめてみる。

この画像にあるなかで、今回やっている内容に関係しそうなものと言えば
メモリに配置されるものであれば
- Adaptive Hash Index
- Buffer Pool
ディスクに配置されるもので
- Tablespace
あたりとなる。
OS Cache についてもまとめる必要がありそう。
Adaptive Hash Index
これはトランザクション機能や信頼性を犠牲にすることなく、ワークロードとバッファプールに十分なメモリをもたせたシステムで、オンメモリデータベースのような機能をもつ。
頻繁にアクセスされるインデックスのページに応じてメモリ内に構築されるハッシュインデックスで、キーに対する値を取得する際に使用される。
MySQL 5.6 における Adaptive Hash Index にはなってしまうが次のドキュメントに B+ Tree と Hash Index の比較が書かれている。
MySQL :: MySQL 5.6 リファレンスマニュアル :: 8.3.8 B ツリーインデックスとハッシュインデックスの比較
Buffer Pool
これは InnoDB にアクセスが行く前に構えているテーブルとインデックス情報をキャッシュするメモリ上の領域を指す。
データそのものにアクセスする際にこれにキャッシュされているとメモリ上の値を直接使用することができるため処理の高速化が予想できる。
また面白いことに、このバッファプールは通常単方向リストとして実装されることが多いが
そのバッファプールリストは2つのサブリストからなり、バッファプールが使用できる領域の 5/8 が比較的直近のデータが格納される領域となっていて
残り 3/8 が比較的古いデータが保持される構造になっている。
こうなっているのは、まずページが読み込まれた時に比較的古いデータが保持されるリストの先頭に追加される。
古いデータを保持するバッファプールリストの要素が読み込まれた場合、それは新しいデータを保持するリストに移動する。
この様にして効率よくメモリを利用する仕組みが取られている。
バッファプールは LRU に基づいて開放される。
MySQL :: MySQL 8.0 Reference Manual :: 15.5.1 Buffer Pool
ざっとみた感じでは CMU Database Systems で紹介されていたものと似ている。
Table Space
これは Database Storage の時にやった内容とは少し異なる方法で実装されている。
そもそもにこれは何かというと実際には、これがデータを保持しているということになっているらしいが、次のような構成を取っている。
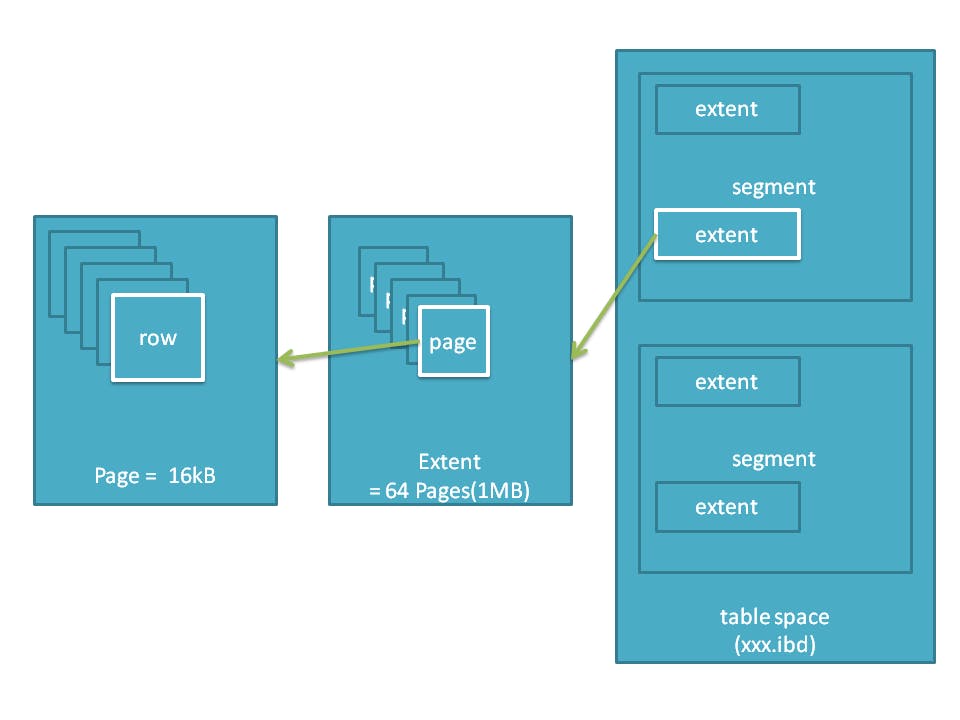
基礎MySQL ~その 5~ InnoDB② - Qiita
テーブルスペース*1の中にセグメントという領域があり、さらにその中に extent という領域*2が存在し
その extent の中にみんな大好き Page *3が格納されている。
テーブルスペースといっても、様々でその中でも特に関係のあるものといえば「File-Per-Table Tablespaces」だと思う。
これを有効にしない状態でデータを書き込むと ibdata が肥大化するなどの懸念があるが、これを有効にすることでテーブル毎にテーブルスペースを独立させることができるため単一ファイルの肥大化を防ぐことができる。
OS Cache と Database Storage
通常、Linux 環境下でファイルにアクセスする場合ファイルキャッシュを経由する。ファイルキャッシュは本来、同一ファイルの読み込み等が行われた際にそれを通すことで読み取りを高速化したり
遅延書き込み機能を使うことでプロセスに対する書き込み性能を向上させる役割がある。
しかし、ほとんどの DBMS にはバッファプールが存在するためファイルキャッシュを経由するとキャッシュを実質的に2つ経由することになり無駄な遅延が発生する。
そのため、 ファイルキャッシュを利用しない Direct I/O という機能*4を使い余分なキャッシュを経由せずにデータをファイルとして扱うようにしている。
これは InnoDB にも搭載されている機能である。