CMU Database Systems をひたすら追っていく ~02 Advanced SQL~
この記事は「 けんつの1人 DBMS アドベントカレンダー Advent Calendar 2019 - Adventar 」 2日目の記事です。
はじめに
どうも、最近なになになけんつです。という始まりをあと 24 回もやらないといけないのかと思うとネタ切れが心配になるけんつです。
ちなみに最近みて面白いなと思った映画は「ローン・サバイバー」です。
例によって CMU Database Systems を進めていきます。今回は「Advanced SQL」です。
今回の動画
余談
この講義、現在進行形で2019年版が展開されているみたい。
この記事を書いている時(2019/11/04)はまだ全部出ていないので 2018 版をもとに書いていく。
Advanced SQL
前回の記事でもリレーショナルモデルと関連して SQL について少し触れたが今回はそれをもっと掘り下げていく。
SQL History
まず SQL とは Structed Query Language の略である。
リレーショナルモデルが提唱されたあと Oracle に採用され、 IBM には「SEQUEL」という SQL が存在した。
IBM はその後、 DB2 を 1983 年にリリースした。
更にその後、 1986 年に ANSI によって規格化され、 1987 年には ISO によって SQL として規格化された。
前回の記事でも述べたように一般に MySQL や PostgreSQL で使用できる SQL は根本的には同じだが数多くの独自構文が存在する理由として、この規格以外の部分はベンダー依存となるためである。
この ANSI/ISO にもいくつかのバージョンが存在し*1
SQL:1999 で RDBMS のための完全なクエリ言語となることを目標とした上に規格化されその後も
SQL:2003, SQL:2008, SQL:2011, SQL:2016 と続いてきた。
準備
今回は MySQL 8.0.16 に講義と同様のテーブルを作成する。
create table student(sid int primary key auto_increment, name varchar(255), login varchar(255),age int, gpa double); create table course(cid varchar(255), name varchar(255)); create table enrolled(sid int, cid varchar(255), grade varchar(2))
本来は外部キー制約だとか Not Null とかを入れるべきだろうけど今回は入れていない。
データも入れて次のようにする。|
MySQL [cmu]> select * from student; +-----+--------+------------+------+------+ | sid | name | login | age | gpa | +-----+--------+------------+------+------+ | 1 | Kanye | kayne@cs | 39 | 4 | | 2 | Bieber | jbieber@cs | 22 | 3.9 | | 3 | Tupac | shakur@cs | 26 | 3.5 | +-----+--------+------------+------+------+ 3 rows in set (0.00 sec) MySQL [cmu]> select * from enrolled; +------+--------+-------+ | sid | cid | grade | +------+--------+-------+ | 1 | 15-445 | C | | 2 | 15-721 | A | | 2 | 15-826 | B | | 3 | 15-445 | B | | 1 | 15-721 | C | +------+--------+-------+ 5 rows in set (0.00 sec) MySQL [cmu]> select * from course; +--------+------------------------------+ | cid | name | +--------+------------------------------+ | 15-445 | Database Systems | | 15-721 | Advanced Database Systems | | 15-826 | Data Mining | | 15-823 | Advanced Topics in Databases | +--------+------------------------------+ 4 rows in set (0.00 sec)
集計
テーブルに含まれる何らかの値を集計する場合は基本的に SELECT を使って出力することが出来る。
さらに集計関数が容易されているはずなのでそれらも使える。
- AVG(col): 指定した列の平均を算出する
- MIN(col): 最小値
- MAX(col): 最大値
- SUM(col): 合計値
- COUNT(col): その行の総数
例)
login の値が @cs で終わるものの総数をカウントする。
select count(*) from student where login like '%@cs'; +----------+ | count(*) | +----------+ | 3 | +----------+ 1 row in set (0.00 sec)
例)
さらに学生の平均GPAを算出する。
SELECT AVG(gpa), COUNT(sid) FROM student WHERE login LIKE '%@cs'; +--------------------+------------+ | AVG(gpa) | COUNT(sid) | +--------------------+------------+ | 3.8000000000000003 | 3 | +--------------------+------------+ 1 row in set (0.04 sec)
今回のテーブルには、列によって重複があるような大きめのテーブルは無いので実例は紹介できないが
重複は DISTINCT でまとめることができる。
文字列操作
前提として SQL 標準規格では文字列は大文字小文字の区別があり、シングルクォートで囲まれたものとなっている。*3
集計の章でも登場しているが Like 句にはパターンマッチを利用することができる。*4
また文字列操作には文字列そのものを変更などできる文字列関数も利用することができる。*5
パターンマッチでは「%」をワイルドカードの様に使える。実際さっき挙げた例では @cs で終わる login カラムの検索に "%@cs" を使っている。
また別の例として例えば学生の名前が丁度5文字の人をカウントする場合、つまり任意の1文字をマッチさせたい場合は 「_」 を使う。
5文字ジャストの場合は「_ _ _ _ _」 とアンダースコアを5つ並べる。
出力のリダイレクト
SQLは Linux のターミナルで出力をリダイレクトするのと同様に出力をリダイレクトすることが出来る。
MySQL [cmu]> insert into stdId (select sid from student); Query OK, 3 rows affected (0.26 sec) Records: 3 Duplicates: 0 Warnings: 0 MySQL [cmu]> select * from stdId; +------+ | id | +------+ | 1 | | 2 | | 3 | +------+ 3 rows in set (0.01 sec)
出力制御
これはよくある ORDER BY, DESC, ASC のようなソート系と LIMIT のような取得の上限を決めるもの。
例) enrolled テーブルから cid = "15-721" のものを取り出して grade を基準に降順で並べる。*6
SELECT sid FROM enrolled WHERE cid = '15-721' ORDER BY grade DESC;
例) enrolled テーブルの上から 3 件を取り出す。
SELECT * FROM enrolled LIMIT 3; +------+--------+-------+ | sid | cid | grade | +------+--------+-------+ | 1 | 15-445 | C | | 2 | 15-721 | A | | 2 | 15-826 | B | +------+--------+-------+
ネストしたクエリ
これはサブクエリなので省略。
Common Table Expressions
CTE は複雑なクエリを記述するために存在していてサブクエリなどの代替とすることができる。
実行されるときに一時的なテーブルを作成すると考えることができる。(そうなのか?)
ちなみにこれは MySQL 8.0 から導入されたのでそれ未満のバージョンでは使えない。
MySQL8.0 の共通テーブル式(CTE)を使ってみよう | スマートスタイル TECH BLOG|データベース&クラウドの最新技術情報を配信
いわゆる WITH 句など。
次のような構文をとる。(MySQL 8.0 をそこまで個人以外で使ったことがないので馴染みがない)
WITH RECURSIVE cteSource (counter) AS ( (SELECT 1) UNION (SELECT counter + 1 FROM cteSource WHERE counter < 10) ) SELECT * FROM cteSource;
おわりに
めちゃくちゃ駆け足になってしまったが、割と知っていることが多かったのでざっと紹介するだけにした。
CTE なんかはあまりつかったことが無いので別途ブログにまとめたい。
で、なんでこんなに途中から駆け足になったかというと書いている途中で過ぎの Database Storage を見ていたら
めちゃくちゃ面白くて早くまとめたくなったから。
というわけで次から Database Storage の回になる。
それから先はバッファだったりハッシュテーブルだったりと面白いことが続く。はず。
これで SQL は終わり。
*2:Comparison of different SQL implementations
*3:MySQL などではダブルクオートも使える。あくまでも ANSI/ISO SQL の話
*4:MySQL :: MySQL 5.6 リファレンスマニュアル :: 3.3.4.7 パターンマッチング
*5:MySQL :: MySQL 5.6 リファレンスマニュアル :: 12.5 文字列関数
*6:昇順の場合は ASC
CMU Database Systems をひたすら追っていく ~01 Relational Data Model~
この記事は「 けんつの1人 DBMS アドベントカレンダー Advent Calendar 2019 - Adventar 」1日目の記事です。
はじめに
どうも、最近やたらと B 級 SF 映画にドハマりしているけんつです。直近だと「リディック:ギャラクシーバトル」がまぁまぁおもしろかったです。
ついでに「ピッチブラック」をその前に見ておくとまぁまぁおもしろいです。
ところで、以前 TL 警備をしていたらこんなブログ記事が登場した。
buildersbox.corp-sansan.com
えぇ、「DBMS」、「Go」、「実装」の単語をみてもう既にやる以外の選択肢がないですね。
データベース好きにはたまらない内容だった。
それで、その記事のなかで紹介されていた「CMU Database Systems」というカーネギーメロン大学のデータベースに関する講義の動画をちょっと見ていたら
めちゃくちゃ面白かったので勉強がてら記事にしていく。
英語、全く得意では無いので割とあやふやな内容になるかもしれませんが何かあればコメントください。
動画リストを見た感じの大まかな流れ
動画内でも紹介されているが、下のレイヤーから上にたどっていく形になっているみたい。
- リレーショナルモデル(今回まとめるやつ)
- Advanced SQL(なにを指しているのか?)
- ストレージ
- バッファプール
- ハッシュテーブル
- ツリーインデックス
- Index Concurrency Control(同時実行制御に関することだと思うけど index はどこに出てくる?)
- Query Processing(??)
- ソートと集約アルゴリズム
- ジョインアルゴリズム
- クエリの最適化
- 並列実行
- Embedded Logic(?)
- Two-Phase Locking Concurrency Control
- Timestamp Ordering Concurrency Control
- Multi-Version Concurrency Control
- Logging Schemes
- Database Recovery
- Distributed OLTP Database
- Distributed OLAP Database
Database とは
現実世界の相互関連的なデータを組織的に、あるいは形式的にまとめたコレクションを扱うものであり
多くのコンピュータアプリケーションの中核を担うもの。
例題
例えば音楽配信サイトを考えた時に曲とアーティスト、アルバム情報を保持するデータベースを考える。
それを実現するために、アーティストの情報とどのアーティストがどのアルバムをリリースしたかという情報を保持することを考える。
これを解決する場合にまず想定されることは CSV(comma-separated value) ファイルなどの Flat File *1を使用すること。
それによって、アプリケーション側のコードでデータ等を管理することが出来る。
データベースとしての Flat Files の問題点
データの整合性をどうやって担保するかという課題が出てくる。
例題をもとに表すならアーティストが各アルバムエントリで同じであることをどのように確認するかという問題が発生する。
さらに言えば誰かがアルバムの発売年を適切でない値に置き換えてしまうかもしれないという問題も起こる。
またひとつのアルバムに複数のアーティストが存在する場合なども実装が難解になってしまう。
整合性の問題の次は、実装上の問題が露呈する。
たとえば、特定のレコードをどのように見つけるか?
複数のアプリケーションで同じデータベースを使うにはどうしたらよいか?
2つのスレッドが同時に書き込みを行ったらどういう挙動をするか?
次に耐久性の問題。
データを更新している最中にマシンがクラッシュしたらレコードはどうなるか?
高可用性のためにデータベースのレプリケーションを複数取りたい場合はどうなるか?
これらを解決するための方法の一つとして DBMS (DataBase Management System) の利用が挙げられる。
DataBase Management System
DataBase Management System (DBMS) とはアプリケーションがデータベース内にデータを保管・分析するためのソフトウェアを指す。
これらいわゆる汎用DBMSは、データベースの定義、作成、クエリ、更新、および管理を可能にするように設計されている。
しかし、初期の DBMS ではデータベースアプリケーションの構築と保守が論理層と物理層が密結合するため困難だった。
またデータベースにデプロイする以前にアプリが実行するクエリを大まかにでも知っておく必要があった。
そのためにリレーショナルモデルが考案された。
リレーショナルモデル
1970 年代に エドガー・コッド (Edgar Frank "Ted" Codd) によって考案された。 *2
複雑なメンテナンスを回避するために、以下の様にデータベースを抽象化する。
データモデル
今回、というかこの一連の内容で取り上げられるのはリレーショナルモデルだが他にも
- Key/Value
- Graph
- Document
- Column-family
- Array/Matrix
- Hierarchical
- Network
などが存在する。
さらに詳しくリレーショナルモデル
リレーショナルモデルにはいくつかの定義が存在する。
まずリレーショナルモデルを取った場合その構造はデータとそのリレーションの定義から構築される。
次に、そのデータベースが保持するデータは制約を満たしていることが確認される。
最後に、それらリレーショナルモデルはデータベースのデータにアクセス、変更する方法が提供される。(SQLのこと?)
リレーションとタプル
リレーショナルモデルを扱うためにまずリレーションとタプルが定義される。
リレーションとは、エンティティを表現する属性と関係を含む順序の無い集合を指す。
タプルは属性値の集合でドメインとも呼ばれる。ただし、値は Atomic/Scalar で Null は全てのドメインのメンバーとされる。
主キー(Primary keys)
主キーは単一のタプルを一意に識別することができる性質を持つ。
ただし一部の DBMS では主キーを定義しない場合、自動的に作成する場合がある。
MySQL においてユニークな数値を主キーとする場合は AUTO_INCREMENT を使うことがよく知られている。
外部キー
外部キーは主キーと似たようなもので、あるリレーションの属性を別の関係のタプルにマッピングする必要があることを指定するものを指す。
DML (Data Manipulation Language)
Data Manipulation Language とは SQL を構築する 3 つの言語の一つ*5でその名の通りデータ操作に関連することを行う言語を指す。
具体的には SELECT, INSERT, UPDATE, DELETE などである。
また関係代数 においてはクエリ、今回で言えば DML とは DBMS が目的の結果を見つけるために使用する戦略を指定することで
関係計算 においては必要なデータのみが指定され検索方法等は指定されないという特性を持つ。
クエリ
リレーショナルモデルが保持するデータをクエリを使って操作することは出来るが、クエリの実装がリレーショナルモデルには影響しないことがクエリとリレーショナルモデルを考える上で重要となってくる。
実際 SQL は MySQL や PostgreSQL に置いて独自構文等を備えているが、ベースとなっているのは ANSI/ISO SQL という標準規格であって
その規格もリレーショナルモデルそのものに関与するものでなくあくまでそのインターフェースにすぎないことがわかる。
おわりに
今回は、あくまで一般的な DBMS とは、リレーショナルモデルとはという話になってしまったが DBMS やリレーショナルモデルは集合論の上にあり
どのような特性をもち、どのように操作するのかは今後の学習において重要な基盤となるのでしっかりと抑えて置きたい。
次回は CMU Database Systems では「Advance SQL」となっているが、その回を飛ばしてストレージの話に移ろうか迷っている。
MySQL の SubQuery と Join をハイパー雑にまとめていく
はじめに
どうも、最近どう頑張っても Netflix で配信されている吹き替え版 ミッションインポッシブル のトム・クルーズが好きになれないけんつです。
今回は最近ふと、MySQL の話とか SQL の話って今までまともにブログにアウトプットしたことがないことに気がついたのでぼちぼちアウトプットしていこうかなと思って書き始めます。
とりあえず、昨日 Twitter の TL で INNER JOIN とか SUBQUERY の話を見かけたのでそのへんから話して行こうかなと思っています。
開発環境
- MySQL 8.0.16
サンプル用のデータには「Sakila Sample Database」を使用する。
MySQL :: Sakila Sample Database
https://dev.mysql.com/doc/sakila/en/
他にもいくつかサンプルデータベースは存在するっぽいけど、今回は↑これを採用する。
MySQL :: Other MySQL Documentation https://dev.mysql.com/doc/index-other.html
サンプルデータ
MySQL :: Other MySQL Documentation https://dev.mysql.com/doc/index-other.html
このサイトから zip かなにかしらでダウンロードしてくる。
そのあとに次の source 文でデータを生成できる。
> source ./path/to/sakila-schema.sql; > source ./path/to/sakila-data.sql;
構造
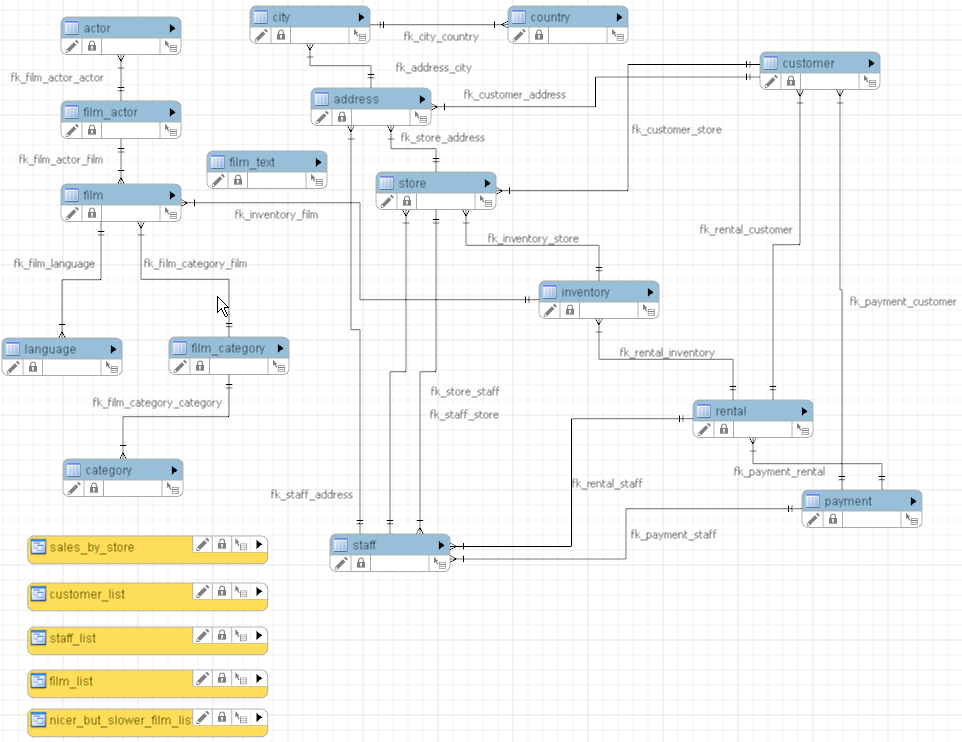
これは公式ドキュメントから拾ってきたものだけど、sakila sample database は↑このような構造を取っている。
色々みていくとわかるのだけど、 テーブルにビューもあれば、ストアードプロシージャもあったりと一通り MySQL で使える機能は大体サンプルとして入っている。
余談
手元の環境を MySQL 5.7 から 8.0 に更新した話
普段は MySQL 5.7 のコンテナを使っていたけど、SUBQUERY のパフォーマンス比較の為に MySQL 8.0 に手元の環境を更新したかったのでこれを機に更新してみた。
例によっていつも docker コンテナで MySQL を使っているが、単にバージョンをあげただけではすんなりと使えなくて困ってしまったのでちょっとだけ紹介したい。
MySQL 8.0 では認証プラグインが変更されている
いつもどおり次のような docker-compose.yaml を書いて雑に使おうとすると次のようなメッセージが出力される。
$ mysql -u <ユーザ> -p<パスワード> -h <ホスト> mysql: [Warning] Using a password on the command line interface can be insecure. ERROR 2059 (HY000): Authentication plugin 'caching_sha2_password' cannot be loaded: /usr/lib64/mysql/plugin/caching_sha2_password.so: cannot open shared object file: No such file or directory
認証プライグインが mysql_native_password でなく caching_sha2_password になっている為にログインできない問題が発生する。
正確には Docker コンテナとして MySQL 8.0 を扱う際にプラグインがロードできていないっぽいのだけどこれの対策にやたら時間がかかってしまった。
結論から言えば、一時的な応急処置として my.cnf にデフォルトで mysql_native_password を使用すると設定を追記しただけなんだけども
なんかもやっとしている。
そのうちそのあたりの内容も記事にしたい。
とりあえず今は応急処置。
SubQuery
サブクエリは、テーブルを加工したりビューにして使い回すわけでも無い時に一時的にテーブルを生成することができるもののことを指す。
例題としてここではサンプルデータにおいて、映画の長さが120分以上で映画カテゴリーが1(種類的には"Action")のものの個数を表示することを考える。
SELECT title FROM film WHERE film.length > 120 AND film.film_id IN ( SELECT film_id FROM film_category WHERE category_id = 1 );
出力結果↓
MySQL [sakila]> SELECT title FROM film WHERE film.length > 120 AND film.film_id IN (SELECT film_id FROM film_category WHERE category_id = 1); +-------------------------+ | title | +-------------------------+ | AMERICAN CIRCUS | | ANTITRUST TOMATOES | | BAREFOOT MANCHURIAN | | BULL SHAWSHANK | | CAMPUS REMEMBER | | CASUALTIES ENCINO | | DARKO DORADO | | DARN FORRESTER | | DRAGON SQUAD | | DREAM PICKUP | | EASY GLADIATOR | | ENTRAPMENT SATISFACTION | | FOOL MOCKINGBIRD | | GOSFORD DONNIE | | KISSING DOLLS | | LAWRENCE LOVE | | MAGNOLIA FORRESTER | | MINDS TRUMAN | | MONTEZUMA COMMAND | | QUEST MUSSOLINI | | SHRUNK DIVINE | | SKY MIRACLE | | SOUTH WAIT | | SPEAKEASY DATE | | STORY SIDE | | UPRISING UPTOWN | | WOMEN DORADO | | WORST BANGER | +-------------------------+
いい感じなんじゃないか。
サブクエリを使うことで一時的にテーブルを作成することが出来るため
だたこの場合、実行計画を確認してみたところ不可解な点があった。
MySQL [sakila]> EXPLAIN SELECT title FROM film WHERE film.length > 120 AND film.film_id IN (SELECT film_id FROM film_category WHERE category_id = 1); +----+-------------+---------------+------------+--------+-----------------------------------+---------------------------+---------+------------------------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+---------------+------------+--------+-----------------------------------+---------------------------+---------+------------------------------+------+----------+-------------+ | 1 | SIMPLE | film_category | NULL | ref | PRIMARY,fk_film_category_category | fk_film_category_category | 1 | const | 64 | 100.00 | Using index | | 1 | SIMPLE | film | NULL | eq_ref | PRIMARY | PRIMARY | 2 | sakila.film_category.film_id | 1 | 33.33 | Using where | +----+-------------+---------------+------------+--------+-----------------------------------+---------------------------+---------+------------------------------+------+----------+-------------+ 2 rows in set, 1 warning (0.00 sec)
なぜ、サブクエリを明示的に使っているのに select_type が SIMPLE になっているんだ・・・。
そこで SHOW WARNINGS を使って実行計画の追加情報を取ってみた。(MySQL5.7以下は EXPLAIN EXTENDED で更に詳細な実行計画を出したあとに行う必要があるっぽい?)
MySQL [sakila]> SHOW WARNINGS; +-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Level | Code | Message | +-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Note | 1003 | /* select#1 */ select `sakila`.`film`.`title` AS `title` from `sakila`.`film_category` join `sakila`.`film` where ((`sakila`.`film`.`film_id` = `sakila`.`film_category`.`film_id`) and (`sakila`.`film_category`.`category_id` = 1) and (`sakila`.`film`.`length` > 120)) | +-------+------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec)
めちゃくちゃ最適化されていた。
バッチリ JOIN されていることからおそらくサブクエリを使うまでしなくてもいい SQL を書いてしまっていたみたい。
といってもサブクエリは外部のクエリに対して依存していなしサブクエリで完結してしまっているからまぁ当然っちゃ当然かもしれない。
ここでなぜ JOIN で最適化されているかというと、それは サブクエリが大抵の場合 JOIN で代替することができるからというのがこのあとの話。
JOIN
複数のテーブルの情報を使う場合はサブクエリだけでなく JOIN を使うこともできる。
JOIN は機能の本質的にはサブクエリに似ているところもあるが具体的には条件に応じてテーブルを結合することができる。
例えば、category 1,2 (具体的にはアクションとアニメーション)が設定されている映画だけサブクエリで無理やり書くならば次のようになる。
(MySQL 5.5 以下なら相関サブクエリ扱いでスロークエリになるはず)
SELECT title FROM film WHERE EXISTS ( SELECT film_id FROM film_category WHERE film_category.category_id < 3 AND film.film_id = film_category.film_id );
そしてこれを JOIN で置き換えると次のようになる。
SELECT title FROM film JOIN film_category ON film.film_id = film_category.film_id AND category_id < 3;
WHERE 句でなく AND で接続してもよい。
JOIN は次に紹介する INNER JOIN で代替が効く場合がおおいため単にあまり使わない。
また JOIN 挙動をわかりやすく説明するためには、 film テーブルを使うとすごく説明が大変なので
film_category と category テーブルを用いて説明する。
それぞれテーブルの先頭10レコードは以下のようになっている。
MySQL [sakila]> select * from film_category limit 10; +---------+-------------+---------------------+ | film_id | category_id | last_update | +---------+-------------+---------------------+ | 1 | 6 | 2006-02-15 05:07:09 | | 2 | 11 | 2006-02-15 05:07:09 | | 3 | 6 | 2006-02-15 05:07:09 | | 4 | 11 | 2006-02-15 05:07:09 | | 5 | 8 | 2006-02-15 05:07:09 | | 6 | 9 | 2006-02-15 05:07:09 | | 7 | 5 | 2006-02-15 05:07:09 | | 8 | 11 | 2006-02-15 05:07:09 | | 9 | 11 | 2006-02-15 05:07:09 | | 10 | 15 | 2006-02-15 05:07:09 | +---------+-------------+---------------------+ 10 rows in set (0.00 sec) MySQL [sakila]> select * from category limit 10; +-------------+-------------+---------------------+ | category_id | name | last_update | +-------------+-------------+---------------------+ | 1 | Action | 2006-02-15 04:46:27 | | 2 | Animation | 2006-02-15 04:46:27 | | 3 | Children | 2006-02-15 04:46:27 | | 4 | Classics | 2006-02-15 04:46:27 | | 5 | Comedy | 2006-02-15 04:46:27 | | 6 | Documentary | 2006-02-15 04:46:27 | | 7 | Drama | 2006-02-15 04:46:27 | | 8 | Family | 2006-02-15 04:46:27 | | 9 | Foreign | 2006-02-15 04:46:27 | | 10 | Games | 2006-02-15 04:46:27 | +-------------+-------------+---------------------+ 10 rows in set (0.01 sec)
これらを JOIN して先頭 20 レコードを取得すると次のようになっている。
MySQL [sakila]> select * from film_category join category limit 20; +---------+-------------+---------------------+-------------+-------------+---------------------+ | film_id | category_id | last_update | category_id | name | last_update | +---------+-------------+---------------------+-------------+-------------+---------------------+ | 1 | 6 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 2 | Animation | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 3 | Children | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 4 | Classics | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 5 | Comedy | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 6 | Documentary | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 7 | Drama | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 8 | Family | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 9 | Foreign | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 10 | Games | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 11 | Horror | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 12 | Music | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 13 | New | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 14 | Sci-Fi | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 15 | Sports | 2006-02-15 04:46:27 | | 1 | 6 | 2006-02-15 05:07:09 | 16 | Travel | 2006-02-15 04:46:27 | | 2 | 11 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 2 | 11 | 2006-02-15 05:07:09 | 2 | Animation | 2006-02-15 04:46:27 | | 2 | 11 | 2006-02-15 05:07:09 | 3 | Children | 2006-02-15 04:46:27 | | 2 | 11 | 2006-02-15 05:07:09 | 4 | Classics | 2006-02-15 04:46:27 | +---------+-------------+---------------------+-------------+-------------+---------------------+ 20 rows in set (0.00 sec)
何がおきているかというと、 film_category の 1 レコード目に対して category が全て結合されている。
結果が肥大化しやすいからあまり使いたくない感じがすごい。
ON 句を使って条件を設定してやればカテゴリ別に結合することもできる。
MySQL [sakila]> select * from film_category join category on film_category.category_id = category.category_id limit 20; +---------+-------------+---------------------+-------------+--------+---------------------+ | film_id | category_id | last_update | category_id | name | last_update | +---------+-------------+---------------------+-------------+--------+---------------------+ | 19 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 21 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 29 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 38 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 56 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 67 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 97 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 105 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 111 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 115 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 126 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 130 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 162 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 194 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 205 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 210 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 212 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 229 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 250 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 252 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | +---------+-------------+---------------------+-------------+--------+---------------------+ 20 rows in set (0.00 sec)
INNER JOIN
いわゆる内部結合と言われるもの。
サンプルデータベースの構造上の特性で inner join に変更しても条件付き join と実行結果が変わらない。
MySQL [sakila]> select * from film_category inner join category on film_category.category_id = category.category_id limit 20; +---------+-------------+---------------------+-------------+--------+---------------------+ | film_id | category_id | last_update | category_id | name | last_update | +---------+-------------+---------------------+-------------+--------+---------------------+ | 19 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 21 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 29 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 38 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 56 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 67 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 97 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 105 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 111 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 115 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 126 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 130 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 162 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 194 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 205 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 210 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 212 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 229 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 250 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 252 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | +---------+-------------+---------------------+-------------+--------+---------------------+ 20 rows in set (0.00 sec)
例題がよくなくてめちゃくちゃ説明しにくいので以下のサイトでも見てくれると助かる。
INNER JOIN はカラムを比較して同じ値を持つレコード同士を結合している。
OUTER JOIN
外部結合と言われるOUTER JOIN には LEFT OUTER JOIN と RIGHT OUTER JOIN の2種類がある。
INNER JOIN とは性質がことなり、OUTER JOIN はカラムが一致しなくても結合する。
LEFT OUTER JOIN
OUTER JOIN で左側のテーブルを起点に結合するため、以下のようになる。
MySQL [sakila]> select * from film_category left outer join category on film_category.category_id = category.category_id limit 20; +---------+-------------+---------------------+-------------+-------------+---------------------+ | film_id | category_id | last_update | category_id | name | last_update | +---------+-------------+---------------------+-------------+-------------+---------------------+ | 1 | 6 | 2006-02-15 05:07:09 | 6 | Documentary | 2006-02-15 04:46:27 | | 2 | 11 | 2006-02-15 05:07:09 | 11 | Horror | 2006-02-15 04:46:27 | | 3 | 6 | 2006-02-15 05:07:09 | 6 | Documentary | 2006-02-15 04:46:27 | | 4 | 11 | 2006-02-15 05:07:09 | 11 | Horror | 2006-02-15 04:46:27 | | 5 | 8 | 2006-02-15 05:07:09 | 8 | Family | 2006-02-15 04:46:27 | | 6 | 9 | 2006-02-15 05:07:09 | 9 | Foreign | 2006-02-15 04:46:27 | | 7 | 5 | 2006-02-15 05:07:09 | 5 | Comedy | 2006-02-15 04:46:27 | | 8 | 11 | 2006-02-15 05:07:09 | 11 | Horror | 2006-02-15 04:46:27 | | 9 | 11 | 2006-02-15 05:07:09 | 11 | Horror | 2006-02-15 04:46:27 | | 10 | 15 | 2006-02-15 05:07:09 | 15 | Sports | 2006-02-15 04:46:27 | | 11 | 9 | 2006-02-15 05:07:09 | 9 | Foreign | 2006-02-15 04:46:27 | | 12 | 12 | 2006-02-15 05:07:09 | 12 | Music | 2006-02-15 04:46:27 | | 13 | 11 | 2006-02-15 05:07:09 | 11 | Horror | 2006-02-15 04:46:27 | | 14 | 4 | 2006-02-15 05:07:09 | 4 | Classics | 2006-02-15 04:46:27 | | 15 | 9 | 2006-02-15 05:07:09 | 9 | Foreign | 2006-02-15 04:46:27 | | 16 | 9 | 2006-02-15 05:07:09 | 9 | Foreign | 2006-02-15 04:46:27 | | 17 | 12 | 2006-02-15 05:07:09 | 12 | Music | 2006-02-15 04:46:27 | | 18 | 2 | 2006-02-15 05:07:09 | 2 | Animation | 2006-02-15 04:46:27 | | 19 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 20 | 12 | 2006-02-15 05:07:09 | 12 | Music | 2006-02-15 04:46:27 | +---------+-------------+---------------------+-------------+-------------+---------------------+ 20 rows in set (0.00 sec)
こうすれば、film_id 別にソートされた状態にすることができたりする。
RIGHT OUTER JOIN
もう予想がつくと思うが右のテーブルを起点に外部結合する。
MySQL [sakila]> select * from film_category right outer join category on film_category.category_id = category.category_id limit 20; +---------+-------------+---------------------+-------------+--------+---------------------+ | film_id | category_id | last_update | category_id | name | last_update | +---------+-------------+---------------------+-------------+--------+---------------------+ | 19 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 21 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 29 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 38 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 56 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 67 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 97 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 105 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 111 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 115 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 126 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 130 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 162 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 194 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 205 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 210 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 212 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 229 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 250 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | | 252 | 1 | 2006-02-15 05:07:09 | 1 | Action | 2006-02-15 04:46:27 | +---------+-------------+---------------------+-------------+--------+---------------------+ 20 rows in set (0.00 sec)
こうすると見辛いがカテゴリ別にソートされた状態で出力することができる。
余談
データが優秀すぎて INNER JOIN と RIGHT JOIN の違いがハイパー説明しにくいので参考文献というなのわかりやすい資料を残しておく。
qiita.com
MySQL の BLACKHOLE Engine とバイナリログを使ってリアルタイムにイベントをハンドリングする何かを作る
はじめに
どうも、最近「FLASH」を見たいがために Hulu を契約したら意外と面白いコンテンツ多くてなんのために契約したのか忘れたけんつです。
いつもは「 Redis はフェチ」なんていうよくわからないことを言っていますが今日は MySQL の話です。
といってもジョブキューに応用したいなって話なのである程度は平常運転です。
何をやるか
MySQL の BLACKHOLE Engine というストレージエンジンとみんな大好きバイナリログを使って雑にジョブキュー的な何かを作ってみようねということをやります。
ジョブキューと言ってしまうと大層なものを考えてしまいそうなので、ただのリアルタイムハンドラーを作ってみただけの話です。
暇になったらジョブキューを作ってみようかなと思っていますが、Redis 使ったほうが絶対いいでしょっていうのが作ってみた感想です。
以下が雑に作ったレポジトリです。
github.com
どうしてやるか
できると思ったから。
BLACKHOLE Engine とは
BLACKHOLE Engine とは「データは受け取るが保存しない」という特性を持つストレージエンジンのこと。Linux で言うところの /dev/null のデータベース版と考えてくれれば大体は良いはず。
dev.mysql.com
詳しくはこのドキュメントを見てもらえればわかると思う。
色々と使いみちはあるが、実データが存在しないから autoincrement が使えなかったりする点とかまぁまぁ注意が必要な部分がある。
そして今回のポイントとして、実データは保持しないがバイナリログにイベントは残るという点もある意味では注目するべき観点なのかなと思っている。
バイナリログとは
バイナリログにはcreate/drop/insert/update/deleteとか、ある意味での CRUD 的な処理がトランザクションが完了した段階でイベントとして記録されるログファイルのこととなっている。
公式ドキュメントは以下のもの。
dev.mysql.com
このブログが割とライトでわかりやすい。
purple-jwl.hateblo.jp
本来はデータのリカバリとかに使われたりする。
実装する
MySQL (Master - Slave 構成)
とりあえず、DB は MySQL 5.7 を使用した。
Master Slave 構成になっているけど、実際は Master だけで出来ることがわかったので Slave は存在しているが使っていない。
両方共バイナリログ周りの設定をしている。
version: '3' services: master: build: ./docker/mysql/master ports: - "3306:3306" environment: - MYSQL_ROOT_PASSWORD=root expose: - "3306" slave: build: ./docker/mysql/slave image: mysql:5.7 depends_on: - master environment: - MYSQL_ROOT_PASSWORD=root - MYSQL_MASTER_SERVER=master - MYSQL_MASTER_ROOT_PASS=root - MYSQL_MASTER_WAIT_TIME=5 expose: - "3306" ports: - "3307:3306"
#master cnf [mysqld] log-bin=/var/log/mysql/bin-log max_binlog_size=256M expire_logs_days=2 innodb_flush_log_at_trx_commit=1 sync_binlog=1 sysdate_is_now server-id=1
#slave cnf [mysqld] log-bin=/var/log/mysql/bin-log max_binlog_size=256M expire_logs_days=2 innodb_flush_log_at_trx_commit=1 sync_binlog=1 sysdate_is_now server-id=2
# init.sql create database blackhole; create table blackhole.queue (msg text) ENGINE = BLACKHOLE;
BlackHole Engine を設定してテーブルを作る。
Golang 実装
package main import ( "context" "fmt" "github.com/siddontang/go-mysql/mysql" "github.com/siddontang/go-mysql/replication" ) func main() { cfg := replication.BinlogSyncerConfig{ ServerID: 1, Flavor: "mysql", Host: "127.0.0.1", Port: 3306, User: "root", Password: "root", } syncer := replication.NewBinlogSyncer(cfg) streamer, err := syncer.StartSync(mysql.Position{}) if err != nil { panic(err) } ch1 := make(chan string, 4) go receiver(ch1) for { ev, _ := streamer.GetEvent(context.Background()) if ev.Header.EventType.String() == "WriteRowsEventV2" { size := int(ev.RawData[32]) value := string(ev.RawData[33:34+size]) ch1 <- value } } } func receiver(ch <-chan string) { for { value := <- ch fmt.Println(value) } }
これだけで出来る。
channel に対してバッファのサイズを 4 としているため、同時に 4 つ以上のデータを受け取った場合 FIFO 的な動作をするようになっている。
また go-mysql が何故か binlog をリアルタイムでハンドリングする機能を搭載しているのでそれを使っている。
これの辛い所
- このジョブキューもどきが死んだとき、どのイベントで死んだかどうかを記録しないと復旧時にバイナリログに記載されているすべてのイベントがロードされてしまうので完了したタスクを再度走らせてしまいそう。
- 一応ログとしてすべてのイベントを持っているが↑に関連してアトミックにイベントを扱うことが難しそう
Position を的確に取るべきだったけど、docker container ベースにしたから権限周りがだるくてやらなかった
- バイナリログのパーサがないと辛い
- Canal を何故かパッケージで認識していないからパーサーが使えなかった
if ev.Header.EventType.String() == "WriteRowsEventV2" { size := int(ev.RawData[32]) value := string(ev.RawData[33:34+size]) ch1 <- value }
何でここで 32 番目を参照しているかというと、 ナマのバイナリでは 32 文字目に Values のサイズが記載されているため
これはテーブルのサイズによるのでパーサーがないと微妙につらい。
まとめ
Redis で Pub/Sub とか使って作った方がいい。
4時間あれば意外といける。
Builderscon に参加してきたから雑にまとめてみる
はじめに
どうも、最近 Redis はフェチとか訳わからんことを言っているけんつです。
今回、縁あって Builderscon に参加してきたので色々と雑に書き残していきます。
スカラシップ
今回 Builderscon に参加するにあたって Classi さんのスカラシップを利用させていただける事となりました。
北海道からの参加となったので正直すごく助かったのと、かなりいろんなことを勉強できる機会を得ることができたので
本当に感謝しか無いです。
classi-scholarship.connpass.com
特に面白かったセッション達
インフラや分散システム周りを中心にそれなりの数、セッションを聞いてみて特に面白かったこれ勉強になったセッション達を雑にまとめます。
Open SKT: メルペイ開発の裏側
トップバッターはメルカリさんの「Open SKT: メルペイ開発の裏側」というセッション
主に分散システムとして決済システムを構築する場合の勘所みたいなところを多く話していた気がする
このセッションではメルカリさんがメルペイというサービスを提供する中でどうやって安心安全を担保していくかという部分にかなり焦点があたっていた。
まずはメルペイのアーキテクチャから触れられていて、マイクロサービスアーキテクチャを採用しているとのこと。
またそれに付随して、開発で重要視されているような事柄も紹介されていた。
このセッションの中で一番おもしろいと思ったところは決済システムないでの一貫性管理をどのようにやっていくかという問題をどう解決するかという所だった。
というのも、自身も大学の研究でマイクロサービスアーキテクチャを採用した機械学習プラットフォームを開発しているが
システム間の強調が難しく、分散システム内でどうやってデータの一貫性を管理しようかと迷っていたという所が大きい。
まず、分散システムにおいてシステム間の強調が難しい場合は中央に処理を集約してしまい
そこでトランザクションを一元管理するというのがよいみたい。
確かに、これは自分でも考えぬいて一箇所で管理した方がシステム全体が複雑になりにくいなどの副次的効果もあると考えてそうしているから納得した。
しかし、次に聞いた話は完全に度肝を抜かれた感じがある。
というのも、エラー処理を例外として扱わずリトライと冪等性の原則を適用するという方法がとても斬新に思えたから。
エラー処理を例外として扱うと確かに複数のコンポーネントが強調して動作している分散システムでは複雑性が増してしまう。
そのため、処理がエラーとなった場合はリトライをし、冪等性を担保して二重処理を防ぐ
その上で継続不可能な場合のみエラーとして検出する
これがかなり合理的に思えた。
というのも、分散システム内の必要なすべての要素において一度処理を行えるかどうかを確かめる(Try)し、
それが実行可能なら処理を確定させ(Confirm)、処理を実行できないのなら中止(Cancel)するという仕組みがあれば確かに
上記のことを満たせるし、システムの複雑性が増さないと思ったから。
これは実際に研究内でどうしようか迷っていたところで、確かにこうすることでエラー処理周りを複雑にしなくて済む一番いい方法だと思った。
この部分の話がかなり面白くて分散システム内で一貫性をどうやって担保するかという問題の解決策は自分の中でかなり斬新な上に衝撃で聞いてみて面白かった。
そのあとに登場した Kyash のアーキテクチャでもトランザクションについては類似した内容が展開されていたから多分これが一番都合のよい仕組みなんだと思う。
RDBのトラブルの現場を追え!
次はそーだいさんの 「RDB のトラブルの現場を追え!」
スロークエリ、不正データ、パフォーマンスチューニングの順番で追っていく。
最初はスロークエリについて紹介されていた。
その中でも最初に来たのはサブクエリの問題。
以下のクエリがなぜ遅いかという問いから始まった。
REPLACE INTO hoge(id, name) SELECT id, name FROM foo AS f INNER JOIN bar AS b ON f.event_id = b.id WHERE f.id in ( SELECT max(event_id) FROM f WHERE canceled_at IS NULL GROUP BY event_id, sheet_id );
これはサブクエリが最高に良くないみたいで MySQL 5.5以下だとスロークエリになってしまう。
5.5 以下では実行計画を見ると「相関サブクエリ」扱いになる。
これによって SELECT id, name に対して、SELCT max(event_id) が走ってしまうためパフォーマンスが落ちるとのこと。
この記事を書くにあたって参考にした記事は以下の2つ
nippondanji.blogspot.com
dev.classmethod.jp
大きいバイナリは直接持たない方がいい
という話と
バルクインサートを利用する場合 MySQLでは LOAD を使った方が早い
といった話も展開された。
また、スロークエリは知らないため(上記のあれが相関サブクエリになってしまうなど)に起こるものと
そもそもどう頑張ってもテーブルの設計が悪いパターンがある。
どっちか判断するために
スロークエリログを見て->実行計画みて->テーブル設計を見直すと大体わかってくるらしい。
その次は、不正データについての話。
制約を守ればいいというだけでなく、INSERT, UPDATE などは処理に成功していても制約が守れているかどうかは判断しにくいため
制約を守れていないデータが入ってしまう場合があるとのこと。(わかる)
さらにその次はパフォーマンスチューニングの話
主にテーブルが絡んだ話だった記憶がある。例題は ISUCON 8 の問題。
特に面白かったのが InnoDB はクラスタインデックスのため INDEX を利用したとき暗黙的にソートされるから GROUP BY などを利用する必要がないというもの。
これは InnoDB の挙動を知っているからできる話で、よく理解していないのなら利用するべきではないと仰っていたが
InnoDB の挙動を考えて SQL を書くとかは考えもしなかったから個人的にこれがめちゃくちゃ面白いなと思った。
InnoDB の挙動もっと追ってみたい。
おわりに
他にも色々なセッションを見に行ってすごく勉強になったのだけど全部まとめていると量が大変なことになるので特に面白かったセッション2つを雑にまとめてみた。
これから時間をみて少しずつ更新していきたい。
今回、初めてこういうカンファレンスに参加したけど、自分の興味ある分野でかなり深い話やめちゃくちゃ勉強になる話をたくさん聞くことが出来てかなり勉強になった。
また一番自分のなかで良かったと思えることは、普段から自分が分散システムに携わっているなかで「うーん、この構成で本当にやっていいのか」とか「この部分の一貫性をどうやって担保しようか」などといったベストアンサーやベストプラクティスは存在しない自分で考えなければならない問題と同じことを解決しようとしていたセッションが多くやっぱり自分だけでなくみんなこれは迷うのかみたいな気付きが得られた上に
それに対する多くな優秀な方が考えた現状ベストプラクティスに最も近い問題解決の手法とそこに至るまでのプロセスを学ぶことが出来たことだと思う。
そのうち聴講するだけでなく、こういうカンファレンスで登壇してみたい。
PHPStan を利用する環境下で call_user_func あたりでハマった話
はじめに
どうも、最近「盾の勇者の成り上がり」の一話をみて「あぁ、この感じの闇堕ち必至展開か」と思ったら想像以上に面白くて徹夜で全話みたけんつです。
今日は Laravel を使っている時に雑に使った call_user_func 関連でめちゃくちゃ詰まったのでその話をまとめていこうかなと思います。
TL;DR
- call_user_func で Array や String で第一引数の Callback を渡しても動く
- PHPStan でコケる
- コケないようにすると、引数を渡せなくなる
- 使わないほうが楽
前提
PHPStan を利用する環境下での話です。
PHP のバージョンは以下の通り。
PHP 7.3.6-1+ubuntu16.04.1+deb.sury.org+1 (cli) (built: May 31 2019 11:06:26) ( NTS )
PHPStan は以下のバージョンを使用する。
Using version ^0.11.12 for phpstan/phpstan
コードは以下のものを前提とします。
<?php // main.php require './vendor/autoload.php'; Sample\A::all();
<?php // A.php namespace Sample; class A { public static function say(string $name, int $age) { echo "Name: {$name}, Age: {$age}\n"; } public static function bye(string $name, int $age) { echo "Bye, Name: {$name}, Age: {$age}\n"; } public static function all() { $name = 'Jack'; $age = 20; $functions = [ 'say', 'bye' ]; foreach ($functions as $function) { call_user_func([__CLASS__, $function], $name, $age); } } }
{ "name": "lrf141/sample", "authors": [ { "name": "lrf141", } ], "require": {}, "require-dev": { "phpstan/phpstan": "^0.11.12" }, "autoload": { "psr-4": { "Sample\\": "./" } } }
何が起こるか
実行することは問題なくできる。
$ php main.php Name: Jack, Age: 20 Bye, Name: Jack, Age: 20
ただ PHPStan を実行すると問題が起こる。
$ ./vendor/bin/phpstan analyze -l 7 ./A.php
1/1 [▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓] 100%
------ ------------------------------------------------------------------------------
Line A.php
------ ------------------------------------------------------------------------------
23 Parameter #1 $function of function call_user_func expects callable(): mixed,
array('Sample\\A', 'bye'|'say') given.
------ ------------------------------------------------------------------------------
[ERROR] Found 1 error
まぁ見事にコケるわけです。
そこで call_user_func の引数を見て見るわけですよ。
https://www.php.net/manual/ja/function.call-user-func.php
call_user_func ( callable $callback [, mixed $parameter [, mixed $... ]] ) : mixed
なるほど?
まぁ確かに PHPStan でもそういう解析結果だしそれはそうだなっていう納得はある。
ここで callable に当てはまらないものってなんだろうかと調べてみる
https://www.php.net/manual/ja/language.types.callable.php
PHP 関数はその名前を単に文字列として渡します。 どのようなビルトインまたはユーザー定義の関数も渡すことができます。 ただし、 array(), echo, empty(), eval(), exit(), isset(), list(), print あるいは unset() といった言語構造はコールバックとしては使えないことに注意しましょう。
なるほど?
原因はこれっぽい。とおもって、公式のサンプルコードを見てみた。
<?php class myclass { static function say_hello() { echo "Hello!\n"; } } $classname = "myclass"; call_user_func(array($classname, 'say_hello')); call_user_func($classname .'::say_hello'); // 5.2.3 以降 $myobject = new myclass(); call_user_func(array($myobject, 'say_hello')); ?>
がっつり array 使っていた。
じゃあ string に変えてみようと思って変えてみた。
call_user_func(__CLASS__.'::'.$function, $name, $age);
$ ./vendor/bin/phpstan analyze -l 7 ./A.php
1/1 [▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓] 100%
------ --------------------------------------------------------------------------------------------
Line A.php
------ --------------------------------------------------------------------------------------------
23 Parameter #1 $function of function call_user_func expects callable(): mixed, string given.
------ --------------------------------------------------------------------------------------------
[ERROR] Found 1 error
なんでそうなった…。
PHP 関数はその名前を単に文字列として渡します。 どのようなビルトインまたはユーザー定義の関数も渡すことができます。
こう書いているのだが…。
これは call_user_func_array でも同様に起こる。
じゃあこれを以下の様に書き換える。
call_user_func(self::$function(), $name, $age);
すると実行時に
$ php main.php
PHP Fatal error: Uncaught ArgumentCountError: Too few arguments to function Sample\A::say(), 0 passed in /home/lrf141/phpProject/waste/A.php on line 23 and exactly 2 expected in /home/lrf141/phpProject/waste/A.php:6
Stack trace:
#0 /home/lrf141/phpProject/waste/A.php(23): Sample\A::say()
#1 /home/lrf141/phpProject/waste/main.php(5): Sample\A::all()
#2 {main}
thrown in /home/lrf141/phpProject/waste/A.php on line 6引数を渡せないっぽい。
self::$function($name, $age);
こうすると解決した。
$ ./vendor/bin/phpstan analyze -l 7 ./A.php
1/1 [▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓] 100%
[OK] No errors
おわりに
誰かどうしてこうなるか教えて欲しい。
追記
Already did :) https://t.co/PCImS37JT0
— Ondřej Mirtes (@OndrejMirtes) July 31, 2019
github.com
PHPStan のバグを踏みぬいたっぽい
画像プロキシを Golang で作った話
はじめに
最近、アマゾンプライムビデオで「ミッションインポッシブル:フォールアウト」を見ていて最後に個人的にあまり好きでない3作目から登場していた元妻でなく前作でいい感じだった美人スパイとトム・クルーズがくっついて「この展開を待っていたああああああああ!!」と静かにガッツポーズしたけんつです。
この前まで Golang で並列処理の勉強をしていたけども急に忙しくなってしまい全く進んでいない現実に向きあいたくなくて今回は Golang で SSL 画像プロキシを作りました。
そのことを雑に書いていこうかなと思っています。
なに作ったか
すごいもの作った感じのタイトルを書いたけど実は参考にしたというか Nodejs 製の画像プロキシを Golang で書きなおしただけ。
参考にしたのはこちら。
結構使われている画像プロキシで
Togetter とか
qiita.com
Qiita とか
qiita.com
探せば色々なサービスで使われていたりする。
Github の README 内に含まれる画像達もこれで配信されているらしい。
というのも、元々外部リソースを参照するときに HTTPS 化するときに全てのコンテンツが HTTPS で提供される必要があるのだが
Togetter のようなキュレーションサイトや Github, Qiita のような外部の画像を扱う可能性のあるものでは常にそれらが HTTPS で提供されているものを使えるというわけではなく
HTTP で提供される外部リソースをユーザが埋め込んでしまう場合がある。
そうなると、 Mix content になってしまいサービス自体を HTTPS で提供できないという問題がある。
そのような問題を上記の Camo では解決できる。具体的には何をするかというと Togetter の Qiita にわかりやすく要点が纏められていた。
実はCamoそのものはSSLプロキシ機能を提供していません。
Camoが提供する最も重要な役割は、プロキシ用URLに共通鍵から生成したダイジェストを含めて暗号化することなのです。画像プロキシサーバを運用する上で懸念されることとして、プロキシ用URLに含まれるオリジン画像のURLを自由に書き換えられた結果、サービサーが想定していないリソースを配信してしまうことなどがあります。
共通鍵で暗号化することで、有効なプロキシ用URLを生成できるのは共通鍵を知るサービサーに限定することが可能になるのです。
これ考えた人、本当に天才ではと思う。
結構苦戦した
いくつか面倒だった部分となんとかこの機能を作るまでに色々と苦戦した部分をまとめる。
Proxy VS Reverse Proxy
最初は Golang で提供されている ReverseProxy 用の構造体を使って作ろうと思ったけど、あれを使うと Golang 側で Request と Response のハンドラーが完全に分離してしまい
'/', '/status' といった通常のレスポンスを返すルーティングを持つものが作りにくかったのでやめた。
普通に HTTP サーバを作るのと同じ要領で作り、画像プロキシのルーティングが呼ばれた時は NewRequest で新しくリクエストを作り直し得た画像情報を ResponseWriter でクライアントに返却するようにしている。
HMAC SHA1
この画像プロキシでは HMAC SHA1 で生成された 40 文字のダイジェストを元に鍵を確認しているがそこが問題だった。
SHA1 を吐けるものは Golang にも存在するがそれを使うと地味に鍵の設定がしづらい。
そこで "crypto/hmac", "crypto/sha1"というパッケージを使った方が簡単だったからそうした。
参考↓
GoでHMAC SHA1を計算するサンプル · GitHub
Url Encoded Path
これは自分の勘違いのせいでめちゃくちゃ苦戦した。
camo は以下の形式でリクエストを受け取る。
http://example.org/digest?url=image-url
http://example.org/digest/image-url
この時、1つ目のパターンでは image-url を url encode された形式で渡しているが2つ目のパターンでは 16 進数に変換された image-url を受け取る必要がある。
これを両方 url encode された URL だと勘違いしてめちゃくちゃハマった。
というのも、なぜ URL Encode された情報をパスに出来ないかというと RFC にはこう書かれている。
https://tools.ietf.org/html/rfc3986#section-6.2.2.2
The percent-encoding mechanism (Section 2.1) is a frequent source of
variance among otherwise identical URIs. In addition to the case
normalization issue noted above, some URI producers percent-encode
octets that do not require percent-encoding, resulting in URIs that
are equivalent to their non-encoded counterparts. These URIs should
be normalized by decoding any percent-encoded octet that corresponds
to an unreserved character, as described in Section 2.3.
正規化されるのだ。
今回は gorilla mux をルーティングに使用したがそれを無効にするオプションがあるのになぜか上手くそれが解決されない問題があって苦戦した。
実際には2つ目の
そして2つ目のパターンは実装がめんどくさすぎるのとテストするときにわざわざ url を 16 進数に変換したものを使うひつようがあるのがまためんどくさくて実装していない。
使い方
ほとんど camo と同じ使い方でいける。
ただ先程も書いたが 2つ目のパターンはまだ実装していないから使えない。
このパターンなら行ける。
おわりに
ミドルウェア書くの楽しい。